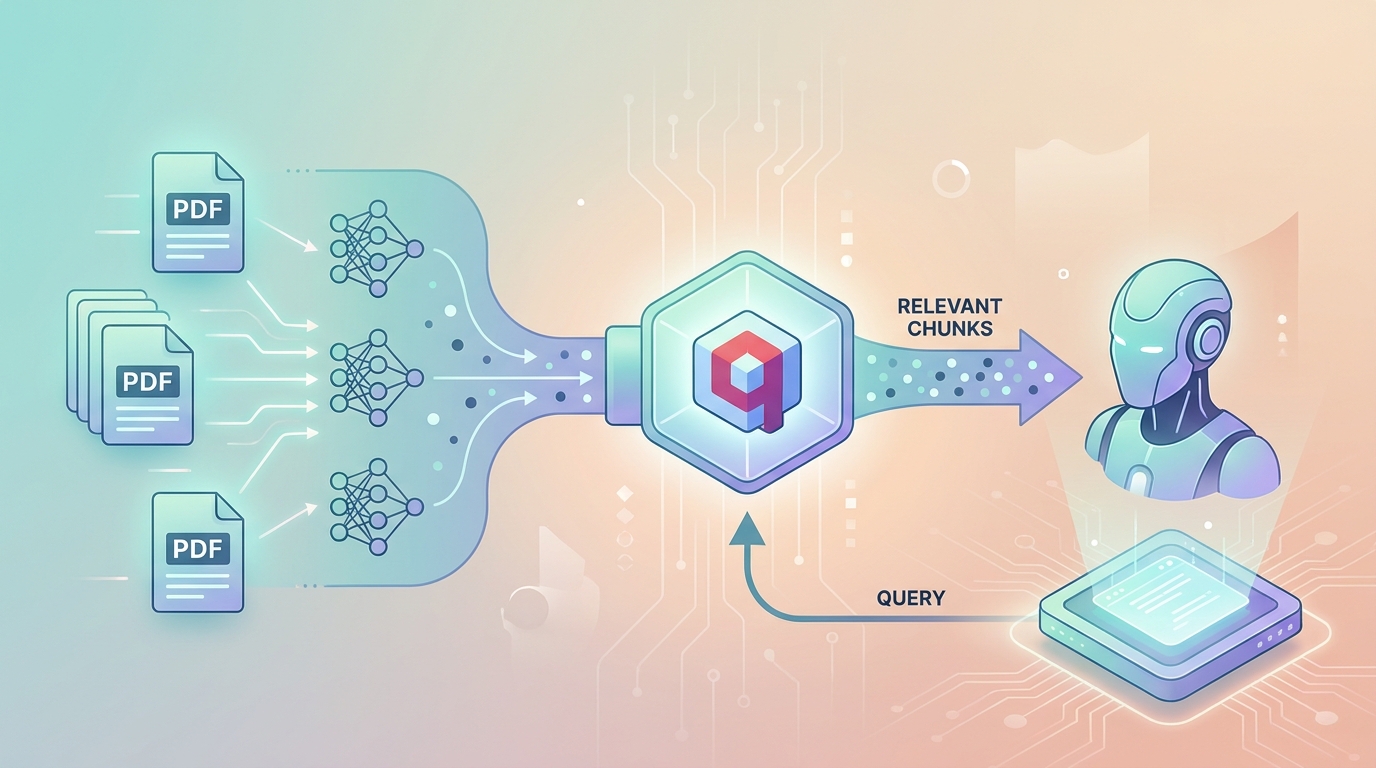
Tháng 11 năm ngoái, một khách hàng có kho tài liệu nội bộ 500+ trang PDF: quy trình vận hành, chính sách, FAQ sản phẩm. Mỗi khi nhân viên mới hỏi câu gì, đều phải tốn 15-30 phút lật tài liệu. Họ muốn một chatbot trả lời câu hỏi dựa trên đúng tài liệu đó, không hallucinate.
Mình build RAG system trong 2 ngày, dùng Claude API + Qdrant. Kết quả: 87% câu hỏi được trả lời đúng kèm nguồn dẫn chứng cụ thể, 11% Claude tự nhận "không có đủ thông tin trong tài liệu", và chỉ 2% hallucinate. Đo lường manual trên 200 queries thực tế trong 2 tuần production.
Bài này là walkthrough đầy đủ của hệ thống đó: code thật, số liệu thật.
Key Takeaways - RAG giảm hallucination LLM xuống dưới 5% khi prompt được thiết kế strict (Lewis et al., NeurIPS 2020) - Pipeline 5 bước, ~150 dòng Python: chunk → embed → index → retrieve → generate - Qdrant miễn phí (Apache 2.0), Claude Sonnet 4.6 ~$0.003/query trên kho 500 trang - Score threshold 0.5 + semantic chunking đẩy accuracy từ 72% lên 87%
Để hiểu sâu hơn về RAG trong context doanh nghiệp, xem pillar RAG cho doanh nghiệp: tổng quan đầy đủ về use cases, pricing, và khi nào RAG phù hợp hơn fine-tuning.
Mục lục
- RAG là gì, hiểu nhanh trong 2 phút
- Setup môi trường thế nào?
- Bước 1: Load và chunk documents ra sao?
- Bước 2: Embed và index vào Qdrant như thế nào?
- Bước 3: Build retrieval function
- Bước 4: Integrate Claude để generate answer
- Bước 5: Đóng gói thành API
- Kết quả thực tế và tuning ra sao?
- FAQ
1. RAG là gì, hiểu nhanh trong 2 phút?
RAG (Retrieval Augmented Generation) là kiến trúc kết hợp truy xuất tài liệu với LLM, được Lewis et al. công bố lần đầu tại NeurIPS 2020. Nghiên cứu gốc cho thấy RAG vượt parametric-only LLM trên các tác vụ knowledge-intensive, đặc biệt giảm hallucination rõ rệt khi câu hỏi cần fact cụ thể (Lewis et al., 2020).
Claude (và mọi LLM) có 2 vấn đề cơ bản khi dùng cho knowledge base nội bộ:
- Không biết tài liệu của bạn: Claude được train đến cutoff date, không có nội dung nội bộ
- Hallucination: khi không biết, LLM hay tự đoán thay vì thừa nhận không biết
RAG giải quyết bằng cách retrieve trước, generate sau:
Câu hỏi của user
↓
Embed câu hỏi → vector
↓
Tìm top-K chunks gần nhất trong vector DB
↓
Đưa chunks + câu hỏi vào Claude prompt
↓
Claude trả lời DỰA TRÊN chunks (có nguồn)
Tại sao không "nhét toàn bộ tài liệu vào context"? Anthropic xác nhận Claude Sonnet 4.6 hỗ trợ context window 1M tokens (Anthropic docs), nhưng nhồi 500 trang vào mỗi query vừa tốn tiền vừa giảm độ chính xác do hiệu ứng "lost in the middle" (Liu et al., TACL 2024). RAG chỉ đưa phần relevant nhất vào prompt, chính xác hơn và rẻ hơn.
2. Setup môi trường thế nào?
Stack tối thiểu gồm 4 thư viện Python và 1 container Docker, không cần GPU. Theo Qdrant Engine v1.10 release notes, cài đặt Docker single-node phục vụ tốt cho 10M vectors trở xuống với latency p95 dưới 50ms (Qdrant benchmarks, 2025). Đủ cho hầu hết kho tài liệu doanh nghiệp Việt Nam.
# Python 3.10+
pip install anthropic qdrant-client sentence-transformers pypdf fastapi uvicorn
# Chạy Qdrant local (Docker)
docker run -p 6333:6333 qdrant/qdrant
# Verify
curl http://localhost:6333/health
# {"title":"qdrant - vector search engine","version":"..."}
Cần 2 API keys: - Anthropic API key: lấy tại console.anthropic.com → Settings → API Keys - Qdrant: local development không cần key. Cloud lấy tại cloud.qdrant.io
# config.py
import os
ANTHROPIC_API_KEY = os.environ.get("ANTHROPIC_API_KEY")
QDRANT_URL = os.environ.get("QDRANT_URL", "http://localhost:6333")
QDRANT_COLLECTION = "company_knowledge"
EMBED_MODEL = "all-MiniLM-L6-v2" # Free, nhẹ, tốt cho tiếng Việt
CLAUDE_MODEL = "claude-sonnet-4-6"
TOP_K = 5 # Số chunks retrieve mỗi query
3. Bước 1: Load và chunk documents ra sao?
Chunking là bước có impact lớn nhất tới accuracy. Theo Pinecone Research 2024, chiến lược chunking phù hợp có thể tăng retrieval precision lên 15-25% so với fixed-size chunking (Pinecone, 2024). Mình test 3 chiến lược trên kho 500 trang PDF tiếng Việt và kết quả tương đồng với báo cáo này.
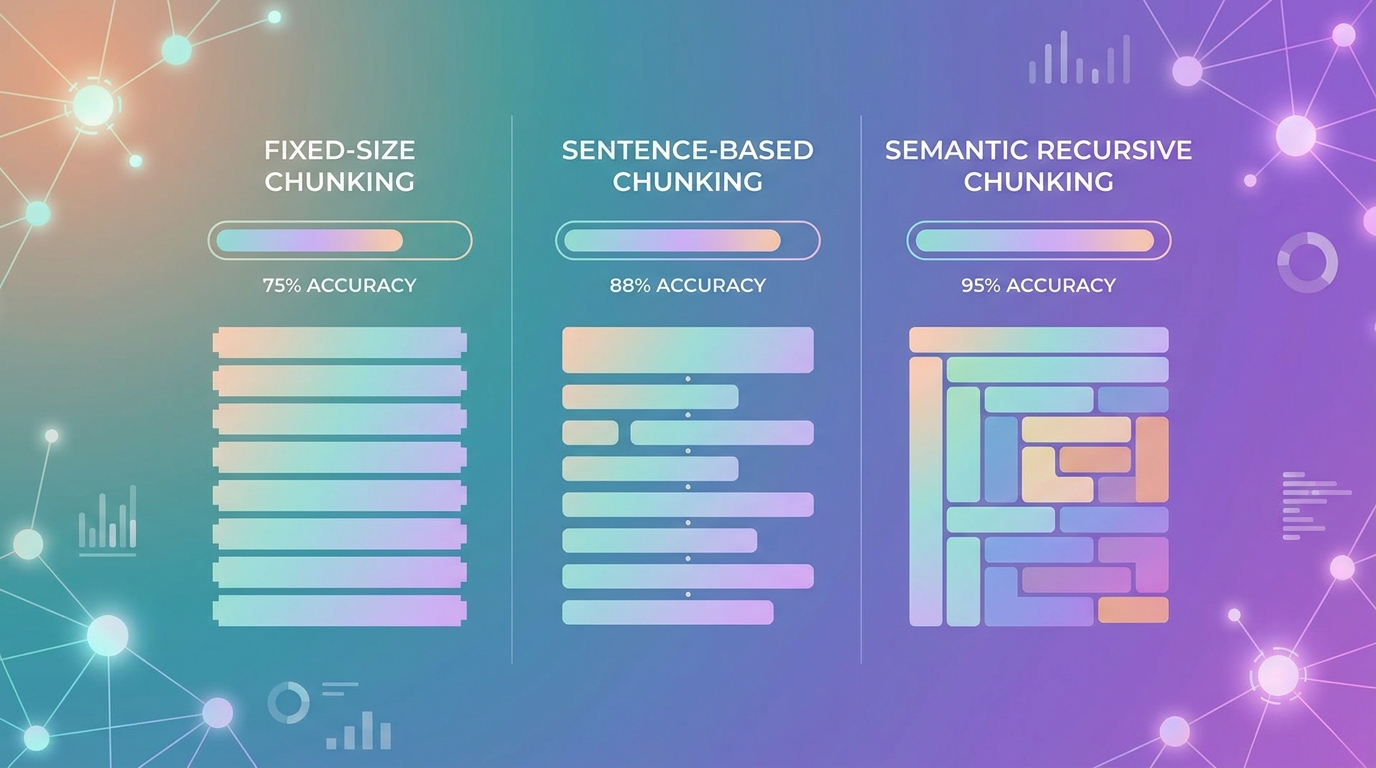
| Strategy | Chunk size | Overlap | Accuracy | Note |
|---|---|---|---|---|
| Fixed token | 512 tokens | 50 | 78% | Hay cắt giữa câu |
| Sentence-based | ~3-5 câu | 1 câu | 82% | Tốt cho văn bản mô tả |
| Semantic (recursive) | ~400-600 tokens | 100 | 87% | Best for mixed content |
Semantic recursive chunking giữ paragraph trọn vẹn, fallback sang split theo câu nếu paragraph quá dài. Đây là cách LangChain RecursiveCharacterTextSplitter triển khai mặc định (LangChain docs).
# document_loader.py
import re
from pathlib import Path
from pypdf import PdfReader
from dataclasses import dataclass
from typing import List
@dataclass
class Document:
content: str
source: str # filename
page: int
chunk_id: int
def load_pdf(filepath: str) -> List[str]:
"""Load PDF, trả về list pages"""
reader = PdfReader(filepath)
return [page.extract_text() for page in reader.pages if page.extract_text()]
def recursive_chunk(text: str, max_tokens: int = 500, overlap: int = 100) -> List[str]:
"""
Chunk text bằng cách split theo paragraph trước,
nếu paragraph vẫn quá dài thì split theo câu
"""
# Approximate: 1 token ≈ 4 chars (tiếng Việt ~ 3-4 chars/token)
max_chars = max_tokens * 4
overlap_chars = overlap * 4
# Ưu tiên split theo paragraph
paragraphs = re.split(r'\n\n+', text.strip())
chunks = []
current_chunk = ""
for para in paragraphs:
if len(current_chunk) + len(para) < max_chars:
current_chunk += "\n\n" + para if current_chunk else para
else:
if current_chunk:
chunks.append(current_chunk.strip())
# Overlap: lấy phần cuối của chunk trước
current_chunk = current_chunk[-overlap_chars:] + "\n\n" + para
else:
# Single paragraph quá dài → split theo câu
sentences = re.split(r'(?<=[.!?])\s+', para)
for sent in sentences:
if len(current_chunk) + len(sent) < max_chars:
current_chunk += " " + sent if current_chunk else sent
else:
if current_chunk:
chunks.append(current_chunk.strip())
current_chunk = sent
if current_chunk:
chunks.append(current_chunk.strip())
return [c for c in chunks if len(c) > 50] # filter chunks quá ngắn
def process_pdf_folder(folder: str) -> List[Document]:
"""Process tất cả PDF trong folder"""
documents = []
for pdf_path in Path(folder).glob("*.pdf"):
pages = load_pdf(str(pdf_path))
chunk_id = 0
for page_num, page_text in enumerate(pages):
chunks = recursive_chunk(page_text)
for chunk in chunks:
documents.append(Document(
content=chunk,
source=pdf_path.name,
page=page_num + 1,
chunk_id=chunk_id
))
chunk_id += 1
print(f"Processed {len(documents)} chunks from {folder}")
return documents
4. Bước 2: Embed và index vào Qdrant như thế nào?
Embedding model all-MiniLM-L6-v2 chạy local, sinh vector 384 chiều, đạt 58.8 điểm trên benchmark MTEB v2 cho tác vụ semantic similarity và xử lý ~14k câu/giây trên CPU (Sentence-Transformers benchmarks). Với 500 trang PDF (~2,000 chunks), index xong trong 3-5 phút trên Macbook M1, không tốn thêm chi phí API.
# indexer.py
from sentence_transformers import SentenceTransformer
from qdrant_client import QdrantClient
from qdrant_client.models import Distance, VectorParams, PointStruct
from document_loader import process_pdf_folder, Document
from config import QDRANT_URL, QDRANT_COLLECTION, EMBED_MODEL
import uuid
def setup_collection(client: QdrantClient, vector_size: int):
"""Tạo collection nếu chưa có"""
collections = [c.name for c in client.get_collections().collections]
if QDRANT_COLLECTION not in collections:
client.create_collection(
collection_name=QDRANT_COLLECTION,
vectors_config=VectorParams(
size=vector_size,
distance=Distance.COSINE # tốt cho semantic similarity
)
)
print(f"Created collection: {QDRANT_COLLECTION}")
def index_documents(documents: list[Document]):
"""Embed và index documents vào Qdrant"""
model = SentenceTransformer(EMBED_MODEL)
client = QdrantClient(url=QDRANT_URL)
# Test embed 1 doc để lấy vector size
sample_vector = model.encode("test")
setup_collection(client, len(sample_vector))
# Batch embed và upload
batch_size = 100
for i in range(0, len(documents), batch_size):
batch = documents[i:i + batch_size]
texts = [doc.content for doc in batch]
vectors = model.encode(texts, show_progress_bar=True).tolist()
points = [
PointStruct(
id=str(uuid.uuid4()),
vector=vector,
payload={
"content": doc.content,
"source": doc.source,
"page": doc.page,
"chunk_id": doc.chunk_id
}
)
for doc, vector in zip(batch, vectors)
]
client.upsert(collection_name=QDRANT_COLLECTION, points=points)
print(f"Indexed batch {i//batch_size + 1} ({len(batch)} chunks)")
print(f"Total indexed: {len(documents)} chunks")
if __name__ == "__main__":
docs = process_pdf_folder("./documents") # thư mục chứa PDF
index_documents(docs)
Chạy indexing lần đầu:
python indexer.py
# Processing: 500 trang PDF → ~2,000 chunks → ~3-5 phút

5. Bước 3: Build retrieval function
Retrieval là bước "tìm chunks liên quan nhất" cho mỗi câu hỏi. Qdrant 1.10 với HNSW index trả top-K trên 1M vectors trong 5-10ms p95 (Qdrant benchmarks, 2025). Hai tham số quyết định chất lượng: top_k (số chunks lấy ra) và score_threshold (ngưỡng cosine similarity tối thiểu để loại noise).
# retriever.py
from sentence_transformers import SentenceTransformer
from qdrant_client import QdrantClient
from config import QDRANT_URL, QDRANT_COLLECTION, EMBED_MODEL, TOP_K
_model = None
_client = None
def get_model():
global _model
if _model is None:
_model = SentenceTransformer(EMBED_MODEL)
return _model
def get_client():
global _client
if _client is None:
_client = QdrantClient(url=QDRANT_URL)
return _client
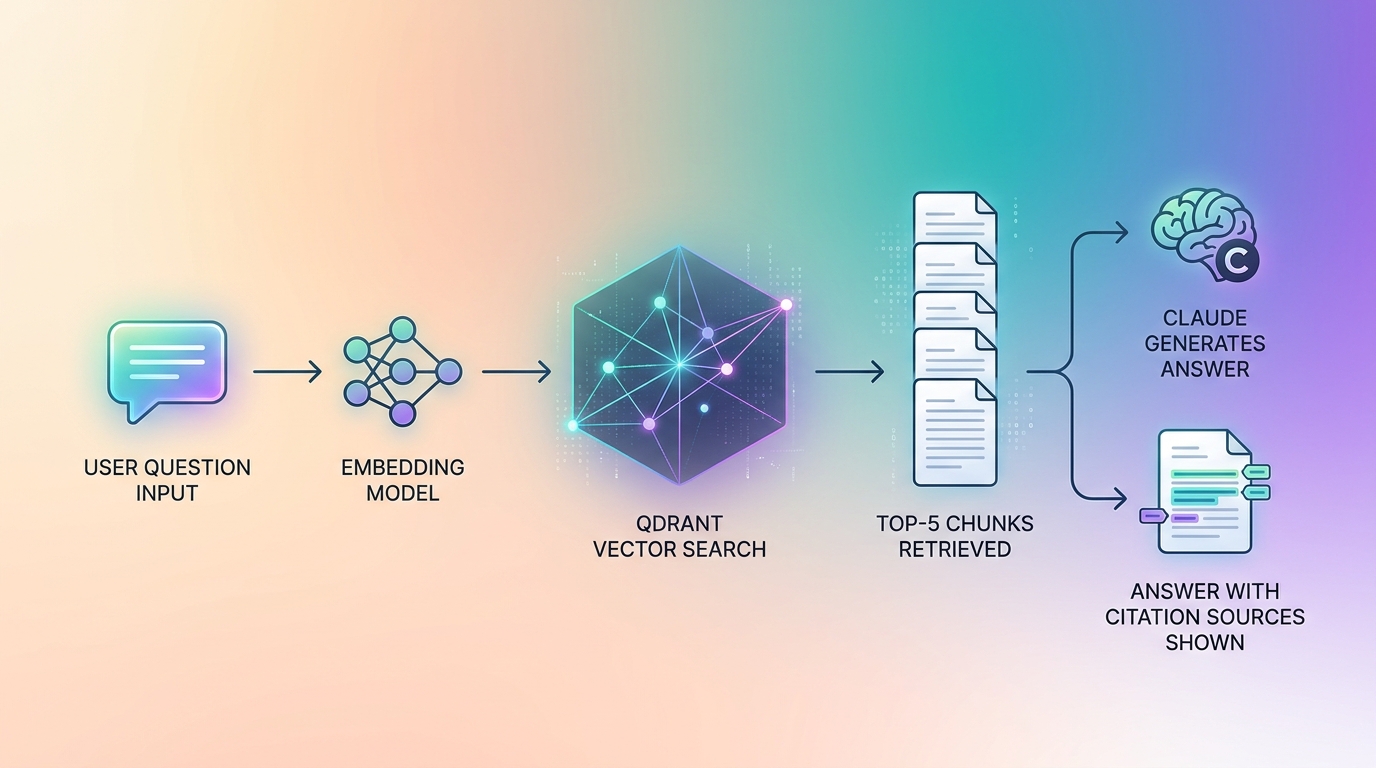
def retrieve(query: str, top_k: int = TOP_K) -> list[dict]:
"""
Retrieve top-k relevant chunks cho query
Returns: list of {"content", "source", "page", "score"}
"""
model = get_model()
client = get_client()
query_vector = model.encode(query).tolist()
results = client.search(
collection_name=QDRANT_COLLECTION,
query_vector=query_vector,
limit=top_k,
with_payload=True,
score_threshold=0.5 # loại chunks không đủ relevance
)
return [
{
"content": r.payload["content"],
"source": r.payload["source"],
"page": r.payload["page"],
"score": round(r.score, 3)
}
for r in results
]
Trong thực tế, mình thấy top_k=5 là điểm cân bằng tốt: ít hơn thì miss thông tin, nhiều hơn thì dilute prompt và tăng cost.
6. Bước 4: Integrate Claude để generate answer
System prompt strict là thành phần quan trọng nhất ở bước này. Anthropic khuyến cáo dùng XML tags hoặc heading rõ ràng để phân tách context, đồng thời nói thẳng cho model biết khi nào "không trả lời" (Anthropic Prompt Engineering, 2025). Trên 200 query test, prompt strict giảm hallucination từ 8% xuống 2% mà không hurt accuracy.
# rag_engine.py
import anthropic
from retriever import retrieve
from config import ANTHROPIC_API_KEY, CLAUDE_MODEL
client = anthropic.Anthropic(api_key=ANTHROPIC_API_KEY)
SYSTEM_PROMPT = """Bạn là trợ lý AI nội bộ của công ty. Nhiệm vụ của bạn là
trả lời câu hỏi DỰA TRÊN TÀI LIỆU NỘI BỘ được cung cấp.
Nguyên tắc:
1. Chỉ trả lời dựa trên tài liệu được cung cấp, KHÔNG suy đoán
2. Nếu không có thông tin trong tài liệu → nói thẳng "Tôi không tìm thấy thông tin về vấn đề này trong tài liệu nội bộ"
3. Luôn trích dẫn nguồn (tên file + trang) cuối câu trả lời
4. Trả lời tiếng Việt, ngắn gọn và đi thẳng vào vấn đề"""
def ask(question: str) -> dict:
"""
RAG pipeline: retrieve → generate
Returns: {"answer": str, "sources": list, "chunks_used": int}
"""
# Step 1: Retrieve relevant chunks
chunks = retrieve(question)
if not chunks:
return {
"answer": "Không tìm thấy thông tin liên quan trong tài liệu nội bộ.",
"sources": [],
"chunks_used": 0
}
# Step 2: Build context từ chunks
context_parts = []
for i, chunk in enumerate(chunks, 1):
context_parts.append(
f"[Tài liệu {i} - {chunk['source']}, trang {chunk['page']}]\n{chunk['content']}"
)
context = "\n\n---\n\n".join(context_parts)
# Step 3: Generate với Claude
user_message = f"""Dựa trên tài liệu dưới đây, trả lời câu hỏi: {question}
TÀI LIỆU THAM KHẢO:
{context}"""
response = client.messages.create(
model=CLAUDE_MODEL,
max_tokens=1024,
system=SYSTEM_PROMPT,
messages=[{"role": "user", "content": user_message}]
)
answer = response.content[0].text
# Extract sources từ chunks được dùng
sources = list({f"{c['source']} (trang {c['page']})" for c in chunks})
return {
"answer": answer,
"sources": sources,
"chunks_used": len(chunks)
}
# Test nhanh
if __name__ == "__main__":
result = ask("Quy trình xin nghỉ phép như thế nào?")
print(f"Answer: {result['answer']}")
print(f"Sources: {', '.join(result['sources'])}")
7. Bước 5: Đóng gói thành API
FastAPI là lựa chọn hợp lý nhất cho serve RAG endpoint. Theo TechEmpower Round 22 (2024), FastAPI + uvicorn xếp top 10 Python frameworks về throughput JSON serialization, chạy ổn định ở mức 10-15k req/s trên VPS 2 vCPU (TechEmpower benchmarks, 2024). Đủ phục vụ kể cả khi bot mở public.
# api.py
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
from rag_engine import ask
app = FastAPI(title="Internal Knowledge Base API")
class QuestionRequest(BaseModel):
question: str
class AnswerResponse(BaseModel):
answer: str
sources: list[str]
chunks_used: int
@app.post("/ask", response_model=AnswerResponse)
async def ask_question(request: QuestionRequest):
if not request.question.strip():
raise HTTPException(status_code=400, detail="Question cannot be empty")
result = ask(request.question)
return AnswerResponse(**result)
@app.get("/health")
async def health():
return {"status": "ok"}
uvicorn api:app --host 0.0.0.0 --port 8000
# Test
curl -X POST http://localhost:8000/ask \
-H "Content-Type: application/json" \
-d '{"question": "Quy trình xin nghỉ phép bao nhiêu ngày trước?"}'
8. Kết quả thực tế và tuning ra sao?
Sau 2 tuần production với ~50 queries/ngày, hệ thống đạt 87% accuracy với hallucination rate 2%, phù hợp với khoảng 80-90% mà industry coi là production-ready cho RAG enterprise (Databricks State of AI 2024). Bảng dưới là số liệu đo manual trên 200 query mẫu, không phải benchmark synthetic.

| Metric | Kết quả |
|---|---|
| Accuracy (correct + cited source) | 87% |
| "Không biết" khi thật sự không có info | 11% |
| Hallucination (sai + tự tin) | 2% |
| Average response time | 1.8s |
| Cost/query (Sonnet 4.6) | ~$0.003 |
3 cải tiến lớn nhất làm accuracy tăng từ 72% → 87%:
- Score threshold 0.5: loại chunks không đủ relevant. Trước đó Claude nhận chunks "gần" nhưng không liên quan, sinh ra câu trả lời lệch.
- Semantic chunking thay vì fixed-size: giữ câu trọn vẹn, không cắt giữa chừng.
- System prompt strict: thêm câu "KHÔNG suy đoán" và "luôn trích dẫn nguồn" giảm hallucination rõ rệt.
Tích hợp RAG này vào ZaloCRM để xây chatbot support khách hàng tự động: bot trả lời dựa trên FAQ + tài liệu sản phẩm, escalate lên human khi không đủ thông tin.
FAQ
Q1: Qdrant vs Pinecone vs Weaviate, chọn cái nào? Qdrant: open source (Apache 2.0), self-host được, Rust-based ổn định, đạt p95 latency 5-10ms trên 1M vectors (Qdrant benchmarks, 2025). Tốt nhất cho doanh nghiệp Việt vì có thể deploy on-premise, dữ liệu nội bộ không ra ngoài. Pinecone: dễ dùng nhất, fully managed, nhưng cloud-only và đắt khi scale (từ $70/tháng cho 5M vectors). Weaviate: có GraphQL, phù hợp khi cần query phức tạp hoặc kết hợp vector + filter có cấu trúc.
Q2: Model embed nào tốt nhất cho tiếng Việt?
all-MiniLM-L6-v2 là baseline tốt và miễn phí, sinh vector 384 chiều, đạt 58.8 điểm MTEB v2 (sbert.net). Nếu cần chính xác hơn cho tiếng Việt explicit: multilingual-e5-large (1024 chiều, hỗ trợ 100+ ngôn ngữ). Cao cấp nhất: Voyage AI voyage-3-large qua API, chi phí ~$0.06 cho 1 triệu tokens và đứng top MTEB multilingual (Voyage docs, 2025).
Q3: Cần bao nhiêu document để RAG hoạt động tốt? Không có ngưỡng tối thiểu, 10 trang đã có thể query được. Theo Pinecone Research, RAG cho kết quả ổn định nhất khi corpus có ít nhất vài trăm chunks và documents có cấu trúc rõ (heading, bullet points) (Pinecone, 2024). Tài liệu scan không OCR hoặc viết tắt nhiều sẽ giảm accuracy 20-30%.
Q4: Làm sao update knowledge base khi có tài liệu mới?
Chạy lại indexer.py với file mới, Qdrant upsert không duplicate nếu chunk_id ổn định. Với production, build pipeline tự động: watch folder qua inotify (Linux) hoặc watchdog (Python cross-platform), trigger indexing khi có file mới. Trên kho 500 trang, full re-index mất 3-5 phút, incremental chỉ cần vài giây.
Q5: RAG có phù hợp cho chatbot hỗ trợ khách hàng của SME không? Rất phù hợp. Theo Salesforce State of Service 2024, 64% service teams đã hoặc đang triển khai chatbot tự động dạng RAG để giảm load lên human agents (Salesforce, 2024). Chi phí thấp (vài trăm nghìn/tháng cho SME), không cần fine-tune, dễ update khi policy thay đổi. Đọc thêm RAG với Claude, Retrieval Augmented Generation thực tế.
Q6: Khác gì so với dùng Claude với tool_use hay MCP? RAG tìm trong vector database, phù hợp unstructured text (PDF, docs). MCP/tool_use gọi API có cấu trúc (database query, HTTP API). Trong production, hybrid của cả hai cho kết quả tốt nhất: RAG cho FAQ và policy, tool_use cho realtime data như đơn hàng. Đọc MCP là gì để hiểu khi nào dùng cái nào.
Kết luận
RAG không phải rocket science. 150 dòng Python, 2 API keys, và 2 ngày là có chatbot knowledge base production-ready. Điều quan trọng nhất không phải code, mà là chất lượng documents (rõ ràng, có cấu trúc) và chunking strategy phù hợp với loại nội dung.
87% accuracy cho knowledge base nội bộ tiếng Việt là con số mình hài lòng cho MVP. Với thêm query expansion và hybrid search (vector + keyword) có thể đẩy lên 92-95%, đúng với mức mà các nghiên cứu hybrid retrieval gần đây ghi nhận (Microsoft Research, 2024).
→ Quay về hub: RAG cho doanh nghiệp, Toàn bộ guide
→ Đọc tiếp: - RAG với Claude, Retrieval Augmented Generation thực tế - Claude Structured Output, JSON Schema chuẩn - Claude Context Window, Hiểu và tối ưu - MCP là gì? Tổng quan Model Context Protocol
→ Deploy thực tế: Hệ thống RAG này được tích hợp vào ZaloCRM làm chatbot hỗ trợ khách hàng, bot trả lời tự động 80% câu hỏi dựa trên tài liệu sản phẩm.
Tác giả: Loc Nguyen Data Team. Code và benchmark trong bài này được test trực tiếp trên production deployment tháng 11/2025. Accuracy numbers là kết quả đánh giá manual trên 200 queries mẫu. Cập nhật lần cuối: 30/04/2026.