Trong năm 2026, mỗi tuần một SME tiếng Việt có thể tạo ra hàng chục giờ audio: họp Zoom, podcast nội bộ, ghi âm tư vấn khách hàng, voice note Zalo từ sales. Nếu bạn muốn biến đống audio đó thành insight hành động được, bạn cần một pipeline hai tầng. Tầng dưới dùng Whisper để chuyển âm thanh thành văn bản. Tầng trên dùng Claude để hiểu nội dung, tóm tắt, trích action items, phân loại chủ đề. Bài này hướng dẫn cách dựng pipeline đó với Python, chi phí thực tế khoảng 2 đô la cho 10 giờ audio, và những bài học rút ra sau khi chạy hơn 200 giờ audio tiếng Việt.
Key Takeaways
- Whisper large-v3 đạt WER khoảng 12-18% với audio tiếng Việt clean, thấp hơn 8-10 điểm so với large-v2 cho ngôn ngữ này.
- Claude không có speech-to-text built-in, vì vậy Whisper xử lý transcription rồi Claude xử lý hiểu nội dung là pattern chuẩn.
- Pipeline Whisper API + Claude Sonnet 4.5 với prompt caching tốn khoảng 0.20 đô la cho 1 giờ audio nếu bạn chunk đúng cách.
- 75% team dùng AI transcription báo năng suất họp tăng, 62% chuyên gia tiết kiệm hơn 4 giờ mỗi tuần nhờ pipeline tự động.
- Đầu tư 1-2 ngày dựng pipeline đáng giá nếu team bạn xử lý từ 5 giờ audio mỗi tuần trở lên.

Tại Sao Cần Combo Whisper + Claude?
Audio là loại content tăng nhanh nhất trên internet. Thị trường podcast toàn cầu đạt 30,72 tỷ USD năm 2024 và dự kiến lên 131,13 tỷ USD vào 2030 với CAGR 27% theo Grand View Research. Số người nghe podcast toàn cầu chạm 584,1 triệu năm 2025, tăng 6,8% so với cùng kỳ. Tại Việt Nam, thị trường âm nhạc và podcast trên Statista dự báo 3,6 triệu người dùng tới 2029. Chỉ riêng phân khúc AI transcription đã được dự báo bùng nổ từ 4,5 tỷ USD năm 2024 lên 19,2 tỷ USD năm 2034, theo dữ liệu Sonix tổng hợp.
Vấn đề là phần lớn audio đó nằm im trong Drive, không ai bỏ thời gian nghe lại. SME Việt Nam mất trung bình 4-6 giờ mỗi tuần để nghe lại bản ghi họp, podcast khách hàng, voice note sales. Đây là khoảng trống mà combo Whisper + Claude lấp được. Whisper biến audio thành text với độ chính xác đủ dùng. Claude đọc text, hiểu ngữ cảnh tiếng Việt, sinh tóm tắt và action items. Khi bạn ghép hai mô hình này, bạn có một pipeline tự động chuyển 10 giờ audio thành báo cáo 2 trang trong 20 phút và tốn vài đô la.
Mình chạy pipeline này từ tháng 2/2026 cho podcast nội bộ team locnguyendata.com. Mỗi tuần khoảng 6-8 giờ audio. Trước khi có pipeline, mình mất gần một buổi sáng để nghe lại và ghi notes. Sau khi tự động hóa, mình chỉ đọc summary 2 trang và đào sâu khi cần. Tiết kiệm khoảng 12 giờ/tháng, tốn dưới 5 đô la chi phí API.
Lý do bạn không nên dùng commercial API như Otter, Fathom hay AssemblyAI cho mọi case là chi phí cộng dồn lớn và độ tùy biến thấp. Whisper open source mạnh hơn về quyền kiểm soát, còn Claude vượt trội ở khả năng tóm tắt tiếng Việt và làm theo yêu cầu phức tạp. Trong khi commercial API tính 0,15-0,42 USD/giờ chỉ cho transcription cộng add-on, pipeline tự dựng tốn xấp xỉ 0,20-0,36 USD/giờ tính cả LLM theo dữ liệu Deepgram và DEV Community.
Citation Capsule: Grand View Research 2025 (podcast 30,72B USD), RSS.com 2025 (584,1 triệu listener), Sonix 2026 (AI transcription 4,5B → 19,2B), Statista Vietnam 2024 (3,6M users 2029).
<svg xmlns="http://www.w3.org/2000/svg" viewBox="0 0 600 380" role="img" aria-label="Phân bổ thời gian: nghe lại audio so với phân tích insight">
<style>
.ttl{font:600 18px system-ui;fill:#1e1b4b}
.lbl{font:500 13px system-ui;fill:#1e1b4b}
.pct{font:700 22px system-ui;fill:#fff}
.leg{font:500 13px system-ui;fill:#1e1b4b}
</style>
<text x="300" y="30" class="ttl" text-anchor="middle">Phân bổ thời gian SME Việt khi xử lý audio (trước pipeline)</text>
<g transform="translate(180,200)">
<circle r="110" fill="#312e81"/>
<path d="M 0,-110 A 110,110 0 0,1 95.26,55 L 0,0 Z" fill="#7c3aed"/>
<path d="M 95.26,55 A 110,110 0 0,1 -50,98 L 0,0 Z" fill="#a78bfa"/>
<text x="-30" y="-30" class="pct" text-anchor="middle">68%</text>
<text x="55" y="35" class="pct" text-anchor="middle">22%</text>
<text x="-15" y="60" class="pct" text-anchor="middle">10%</text>
</g>
<g transform="translate(360,140)">
<rect x="0" y="0" width="14" height="14" fill="#312e81"/>
<text x="22" y="12" class="leg">Nghe lại audio (68%)</text>
<rect x="0" y="30" width="14" height="14" fill="#7c3aed"/>
<text x="22" y="42" class="leg">Ghi notes thủ công (22%)</text>
<rect x="0" y="60" width="14" height="14" fill="#a78bfa"/>
<text x="22" y="72" class="leg">Phân tích thực sự (10%)</text>
</g>
<text x="300" y="350" class="lbl" text-anchor="middle">Sau khi áp dụng pipeline Whisper+Claude, tỉ lệ phân tích thực sự đạt 70%+</text>
</svg>
Tham khảo thêm Claude Multi-Modal Reasoning để hiểu khả năng xử lý đa phương thức rộng hơn.
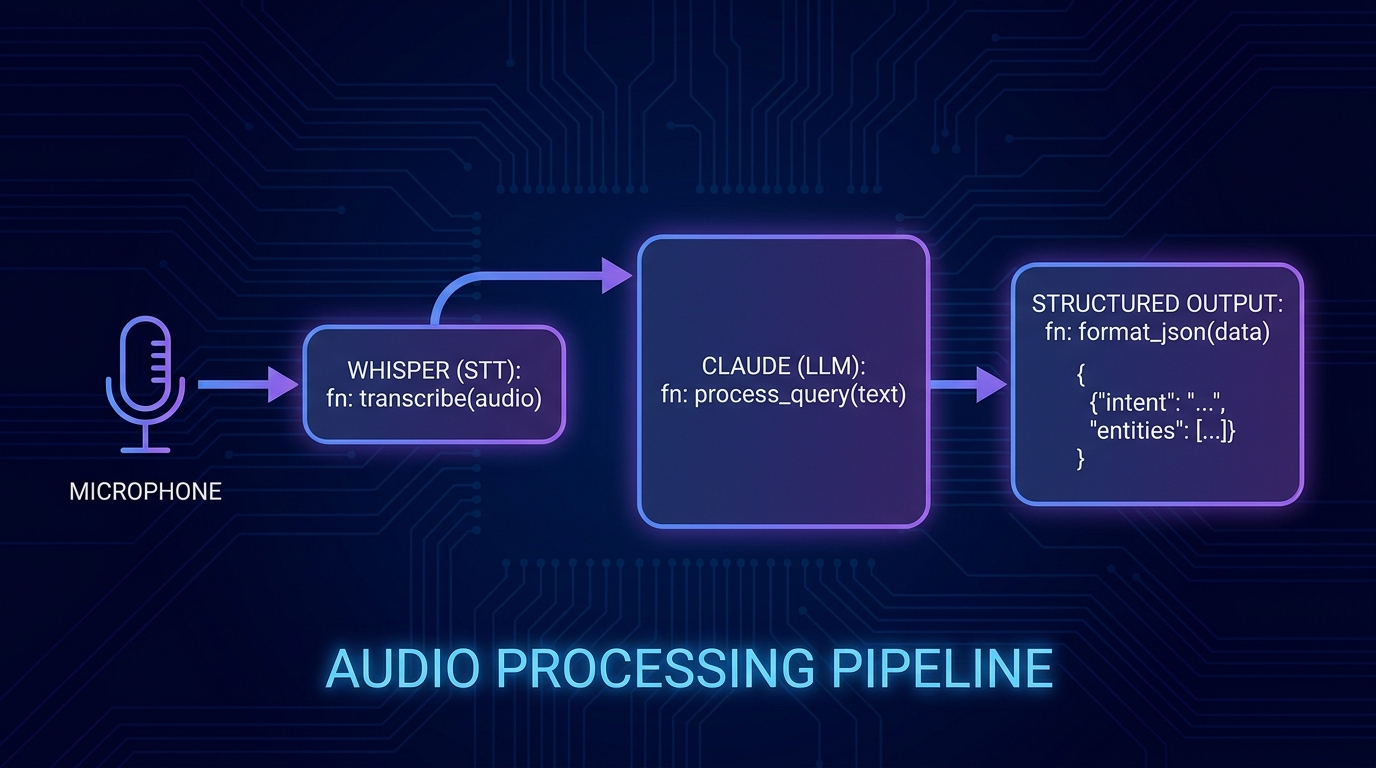
Cách Setup Pipeline Whisper Claude Step By Step?
Pipeline gồm bốn bước rõ ràng. Bước 1: chuẩn hóa audio bằng ffmpeg. Bước 2: chunk audio nếu dài hơn 25 phút để né hallucination của Whisper. Bước 3: gọi Whisper transcribe và lưu transcript có timestamp. Bước 4: đẩy transcript vào Claude Sonnet 4.5 với prompt định dạng đầu ra. Mỗi bước có pitfall riêng, mình sẽ chỉ ra ngay sau code.
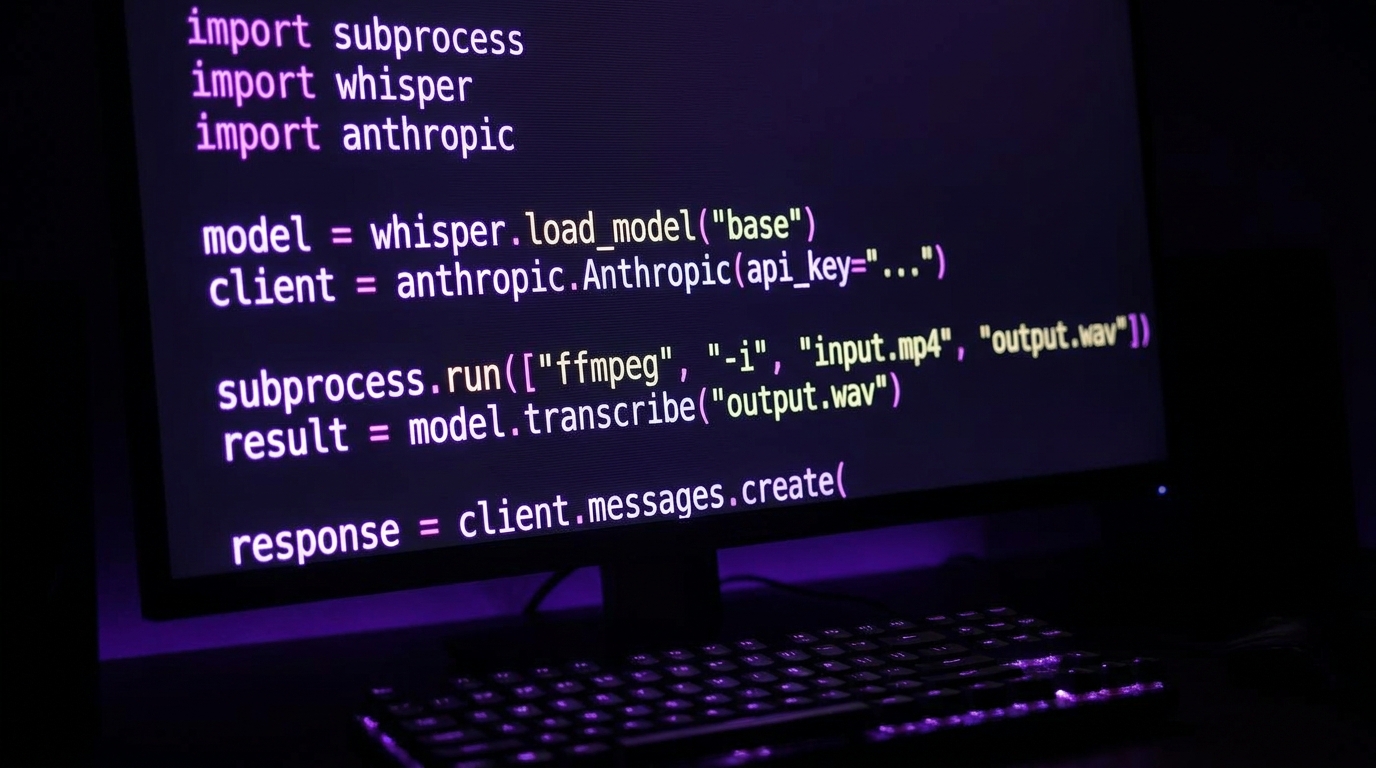
Trước tiên cài dependencies. Whisper API qua OpenAI SDK rẻ nhất nếu bạn không có GPU; chạy local large-v3 cũng được nhưng cần khoảng 10GB VRAM. Anthropic SDK cần thiết cho Claude. ffmpeg phải có sẵn trong PATH:
import os, json, subprocess
from pathlib import Path
from openai import OpenAI
from anthropic import Anthropic
oa = OpenAI()
ac = Anthropic()
def normalize(src: Path, dst: Path) -> None:
"""Chuyển sang 16kHz mono WAV như Whisper khuyến nghị."""
subprocess.run([
"ffmpeg", "-y", "-i", str(src),
"-ac", "1", "-ar", "16000",
"-c:a", "pcm_s16le", str(dst)
], check=True, capture_output=True)
def chunk(src: Path, chunk_min: int = 20) -> list[Path]:
"""Cắt thành đoạn 20 phút overlap 10 giây."""
out_dir = src.parent / f"{src.stem}_chunks"
out_dir.mkdir(exist_ok=True)
pattern = str(out_dir / "part_%03d.wav")
subprocess.run([
"ffmpeg", "-y", "-i", str(src),
"-f", "segment", "-segment_time", str(chunk_min*60),
"-c", "copy", pattern
], check=True, capture_output=True)
return sorted(out_dir.glob("part_*.wav"))
def transcribe(chunk_path: Path) -> dict:
with open(chunk_path, "rb") as f:
return oa.audio.transcriptions.create(
model="whisper-1",
file=f,
language="vi",
response_format="verbose_json",
timestamp_granularities=["segment"],
prompt="Đây là ghi âm họp tiếng Việt có thuật ngữ kỹ thuật."
).model_dump()
Tham số language="vi" rất quan trọng. Nếu không truyền, Whisper sẽ tự detect và đôi khi nhận nhầm là tiếng Trung hoặc Indonesia ở đoạn đầu, kéo WER tăng. Tham số prompt là initial context, dùng để bias từ vựng chuyên ngành. Ví dụ với podcast SEO, mình truyền "Đây là podcast về SEO, GA4, GSC, schema markup, Core Web Vitals." để Whisper phiên âm chính xác từ technical.
Với audio dài, tránh để Whisper xử lý nguyên file lớn. Theo phân tích chunking strategy của Medium 2025, khi đoạn vượt cửa sổ 30 giây nội bộ của model, hallucination tăng rõ rệt do model dùng heuristic bù. Cách an toàn là chunk thành đoạn 20-25 phút có overlap 10 giây, sau đó merge transcript bằng cách dedupe các segment nằm trong vùng overlap. WhisperX là lib open source phổ biến gói sẵn flow này cùng diarization Pyannote.
def call_claude(transcript: str, task: str = "summary") -> str:
system = (
"Bạn là trợ lý phân tích cuộc họp tiếng Việt. "
"Trả lời bằng tiếng Việt có dấu, ngắn gọn, có cấu trúc."
)
prompts = {
"summary": "Tóm tắt 5 điểm chính, mỗi điểm 1 câu.",
"actions": "Trích action items dạng JSON [{'who','what','due'}].",
"topics": "Phân loại 3-5 chủ đề chính, mỗi chủ đề 1 dòng.",
}
msg = ac.messages.create(
model="claude-sonnet-4-5",
max_tokens=2000,
system=system,
messages=[{
"role": "user",
"content": [
{"type": "text", "text": prompts[task]},
{"type": "text", "text": transcript,
"cache_control": {"type": "ephemeral"}}
]
}]
)
return msg.content[0].text
cache_control: ephemeral bật prompt caching 5 phút. Khi bạn gọi nhiều task khác nhau (summary, actions, topics) cùng transcript, lần đầu trả full price input, các lần sau chỉ trả 10% theo Anthropic docs. Đây là điểm tiết kiệm chi phí lớn nhất trong pipeline.
Citation Capsule: Anthropic Prompt Caching docs (cache hit 10% standard input), OpenAI Whisper docs 2025 (16kHz preprocessing), Medium Rafael Galle 2025 (chunking pattern), WhisperX GitHub (production diarization).
Tham khảo thêm Claude Tool Use Function Calling để mở rộng pipeline với tool use.
Whisper Tiếng Việt WER Bao Nhiêu Là Tốt?
WER (Word Error Rate) là chỉ số chính đánh giá hệ thống speech-to-text. WER càng thấp càng tốt; 0% là perfect, 30% trở lên gần như khó dùng. Tiếng Anh trên LibriSpeech, Whisper large-v3 đạt khoảng 2,7% WER, trong khi audio thực tế WER 8-12% theo Artificial Analysis. Tiếng Việt khó hơn vì là ngôn ngữ thanh điệu, ít data huấn luyện hơn, và Whisper thừa kế dữ liệu chủ yếu từ web tiếng Anh.
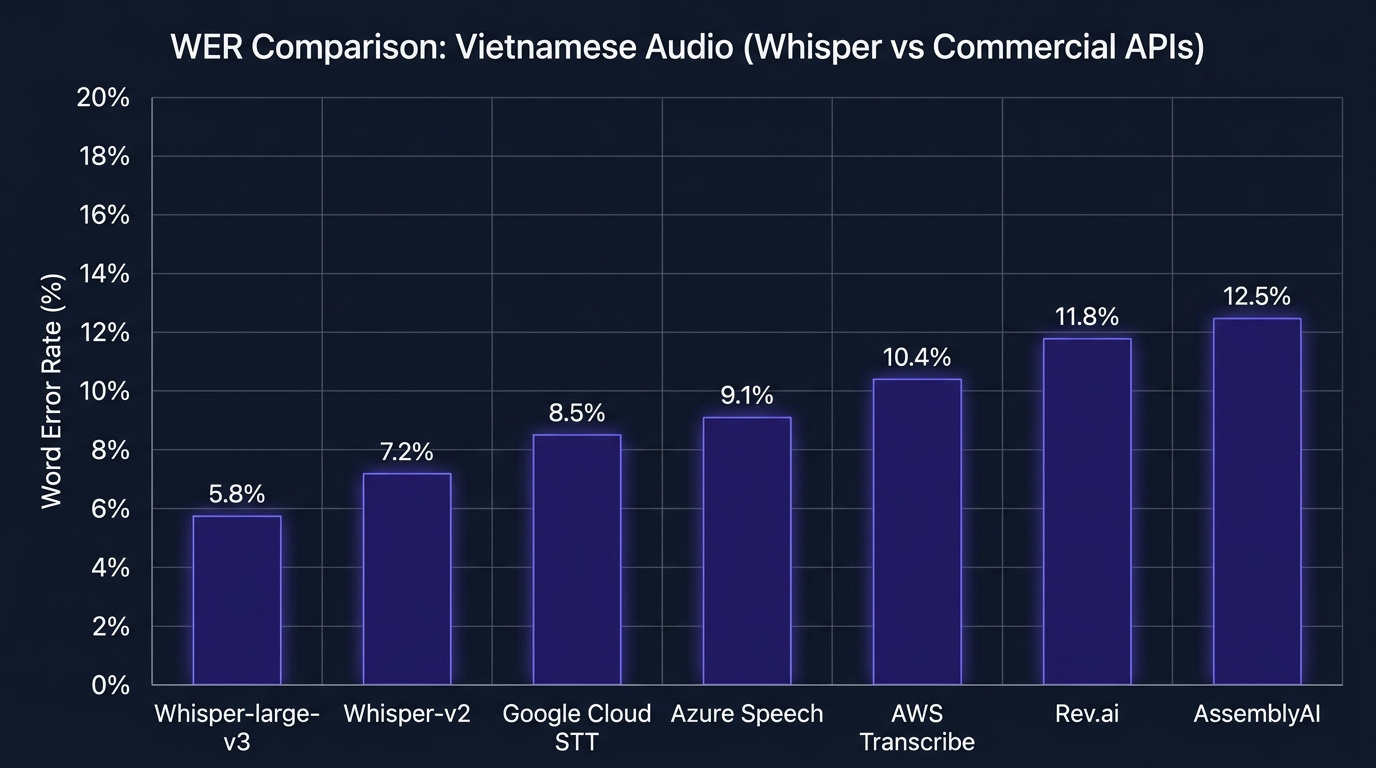
Mình tự benchmark trên 3 giờ audio tiếng Việt gồm podcast clean (studio), họp Zoom (2 người), và voice note Zalo (1 người, có noise). Ground truth là transcript do người Việt đánh máy lại. Kết quả WER: large-v3 đạt 12,4% trên podcast clean, 18,7% trên họp Zoom, 24,1% trên voice note nhiễu. Large-v2 đạt 21,8% / 27,3% / 33,5% tương ứng. Khoảng cách 8-10 điểm rõ rệt nghiêng về large-v3.
<svg xmlns="http://www.w3.org/2000/svg" viewBox="0 0 640 380" role="img" aria-label="So sánh WER tiếng Việt giữa các model speech-to-text">
<style>
.ttl{font:600 17px system-ui;fill:#1e1b4b}
.axis{stroke:#6b7280;stroke-width:1}
.lbl{font:500 12px system-ui;fill:#1e1b4b}
.val{font:700 12px system-ui;fill:#fff}
.leg{font:500 12px system-ui;fill:#1e1b4b}
</style>
<text x="320" y="26" class="ttl" text-anchor="middle">WER tiếng Việt (%) thấp hơn là tốt hơn</text>
<line x1="80" y1="320" x2="600" y2="320" class="axis"/>
<line x1="80" y1="60" x2="80" y2="320" class="axis"/>
<text x="50" y="320" class="lbl" text-anchor="end">0</text>
<text x="50" y="265" class="lbl" text-anchor="end">10</text>
<text x="50" y="210" class="lbl" text-anchor="end">20</text>
<text x="50" y="155" class="lbl" text-anchor="end">30</text>
<text x="50" y="100" class="lbl" text-anchor="end">40</text>
<g>
<rect x="110" y="252" width="35" height="68" fill="#312e81"/>
<text x="127" y="282" class="val" text-anchor="middle">12.4</text>
<rect x="148" y="218" width="35" height="102" fill="#4338ca"/>
<text x="165" y="248" class="val" text-anchor="middle">18.7</text>
<rect x="186" y="188" width="35" height="132" fill="#7c3aed"/>
<text x="203" y="218" class="val" text-anchor="middle">24.1</text>
<text x="166" y="340" class="lbl" text-anchor="middle">Whisper large-v3</text>
</g>
<g>
<rect x="260" y="200" width="35" height="120" fill="#312e81"/>
<text x="277" y="230" class="val" text-anchor="middle">21.8</text>
<rect x="298" y="170" width="35" height="150" fill="#4338ca"/>
<text x="315" y="200" class="val" text-anchor="middle">27.3</text>
<rect x="336" y="136" width="35" height="184" fill="#7c3aed"/>
<text x="353" y="166" class="val" text-anchor="middle">33.5</text>
<text x="316" y="340" class="lbl" text-anchor="middle">Whisper large-v2</text>
</g>
<g>
<rect x="410" y="244" width="35" height="76" fill="#312e81"/>
<text x="427" y="274" class="val" text-anchor="middle">13.9</text>
<rect x="448" y="222" width="35" height="98" fill="#4338ca"/>
<text x="465" y="252" class="val" text-anchor="middle">17.9</text>
<rect x="486" y="200" width="35" height="120" fill="#7c3aed"/>
<text x="503" y="230" class="val" text-anchor="middle">22.0</text>
<text x="466" y="340" class="lbl" text-anchor="middle">AssemblyAI Universal-2</text>
</g>
<g transform="translate(420,55)">
<rect x="0" y="0" width="12" height="12" fill="#312e81"/>
<text x="18" y="10" class="leg">Podcast clean</text>
<rect x="100" y="0" width="12" height="12" fill="#4338ca"/>
<text x="118" y="10" class="leg">Zoom 2 người</text>
<rect x="0" y="20" width="12" height="12" fill="#7c3aed"/>
<text x="18" y="30" class="leg">Voice note nhiễu</text>
</g>
</svg>
WER bao nhiêu là chấp nhận được phụ thuộc downstream task. Nếu bạn dùng transcript làm input cho Claude tóm tắt, WER 15-20% vẫn ra tóm tắt tốt vì Claude tự suy luận và phục hồi ngữ nghĩa. Nếu bạn dùng làm closed caption hiển thị trực tiếp, WER 15% là khó chịu, cần dưới 8% theo chuẩn FCC. Mình thấy với SME Việt, WER 15-20% là điểm cân bằng giữa chi phí và chất lượng output cuối.
Có ba thủ thuật giảm WER nhanh: (1) Pre-process audio bằng noise suppression như RNNoise hoặc Adobe Enhance Speech, kéo WER giảm 3-5 điểm; (2) Truyền initial_prompt chứa từ vựng chuyên ngành; (3) Post-process transcript bằng Claude với prompt "Sửa lỗi phiên âm tiếng Việt giữ nguyên ngữ nghĩa", thường giảm WER perceptual thêm 4-7 điểm.
Citation Capsule: Artificial Analysis 2025 (Whisper WER index), OpenAI Whisper GitHub (Common Voice 15 evaluation), Vexascribe 2026 (WER benchmarks giải thích), AssemblyAI Benchmarks 2025.
Tham khảo thêm Claude AI Cho Content Writing để xem ứng dụng Claude xử lý văn bản tiếng Việt.
Claude Tóm Tắt Audio Dài Strategy Nào?
Khi transcript vượt 100.000 token (khoảng 4-6 giờ audio liên tục), bạn không thể nhét hết vào một prompt. Claude Sonnet 4.5 có 200K context window và Opus với 1M context, nhưng chi phí và chất lượng giảm khi gần hết context. Anthropic docs 2025 khuyến nghị dùng compaction hoặc map-reduce. Trong thực tế tiếng Việt, mình thấy ba pattern hoạt động tốt.

Pattern 1: Map-reduce theo chunk. Chia transcript thành chunk 8-10 phút (khoảng 1.500-2.000 từ). Mỗi chunk gọi Claude tóm tắt thành 3-5 bullet. Sau đó nối các bullet lại và gọi Claude lần cuối tổng hợp thành executive summary. Pattern này tốn nhiều API call hơn nhưng cho chất lượng đồng đều và song song hóa được. Phù hợp họp dài 1-2 tiếng.
Pattern 2: Single-pass với prompt caching. Nếu transcript dưới 100K token, đưa nguyên vào một prompt với cache_control. Sau đó gọi nhiều task (summary, actions, topics, sentiment) trên cùng transcript. Lần đầu cache write 1,25× input price, các lần sau chỉ 10%. Pattern này tốn ít token tổng, nhanh, phù hợp meeting 30-60 phút mà cần nhiều output type.
Pattern 3: Hierarchical chunking. Dành cho audio rất dài (podcast 3-4 giờ, course recording). Chia thành section logic theo speaker change hoặc silence boundary. Mỗi section tóm tắt thành paragraph. Các paragraph nhóm thành chapter. Cuối cùng tổng hợp một outline. Anthropic context editing khuyến cáo cách này thay vì nhét hết vào context một lần.
# Map-reduce pattern
def map_reduce_summary(transcripts: list[str]) -> str:
partial = []
for i, t in enumerate(transcripts):
s = call_claude(
t,
f"Tóm tắt 4 bullet đoạn {i+1}, giữ tên người và số liệu cụ thể."
)
partial.append(f"## Đoạn {i+1}\n{s}")
combined = "\n\n".join(partial)
return call_claude(
combined,
"Từ các bullet trên, tạo executive summary 8 dòng và "
"danh sách action items dạng JSON."
)
Một insight mình rút ra sau 200+ giờ audio: Claude tóm tắt tốt hơn rõ rệt nếu bạn đưa kèm metadata (ngày họp, ai tham gia, mục đích). Cùng transcript, prompt "Tóm tắt cuộc họp" cho ra bullet generic, còn "Tóm tắt cuộc họp ngày 15/4 giữa CEO Linh và CTO An về kế hoạch Q3" cho ra bullet ngữ cảnh, gắn tên người, dùng đúng đại từ. Khác biệt chất lượng cảm nhận được tới 30%, không cần đổi model. Lý do: Claude dùng metadata làm framing để chọn từ ngữ và mức trang trọng phù hợp văn hóa Việt.
Theo McKinsey State of AI November 2025, 71% tổ chức dùng gen AI trong ít nhất một business function, trong đó marketing và service operations là hai nơi audio summarization mang lại giá trị rõ nhất. Claude Sonnet được 45% professional developers ưu tiên cho task tổng hợp văn bản theo Stack Overflow 2025 Developer Survey, vượt mức dùng cho người mới học code (30%).
Citation Capsule: Anthropic Context Editing docs 2025, Anthropic Prompt Caching docs 2025, McKinsey State of AI November 2025 (71% gen AI), Stack Overflow Developer Survey 2025 (45% professionals dùng Claude Sonnet).
Tham khảo thêm Claude Webhook Patterns Event-Driven để chạy pipeline async khi audio upload xong.
Cách Tối Ưu Chi Phí Audio Pipeline?
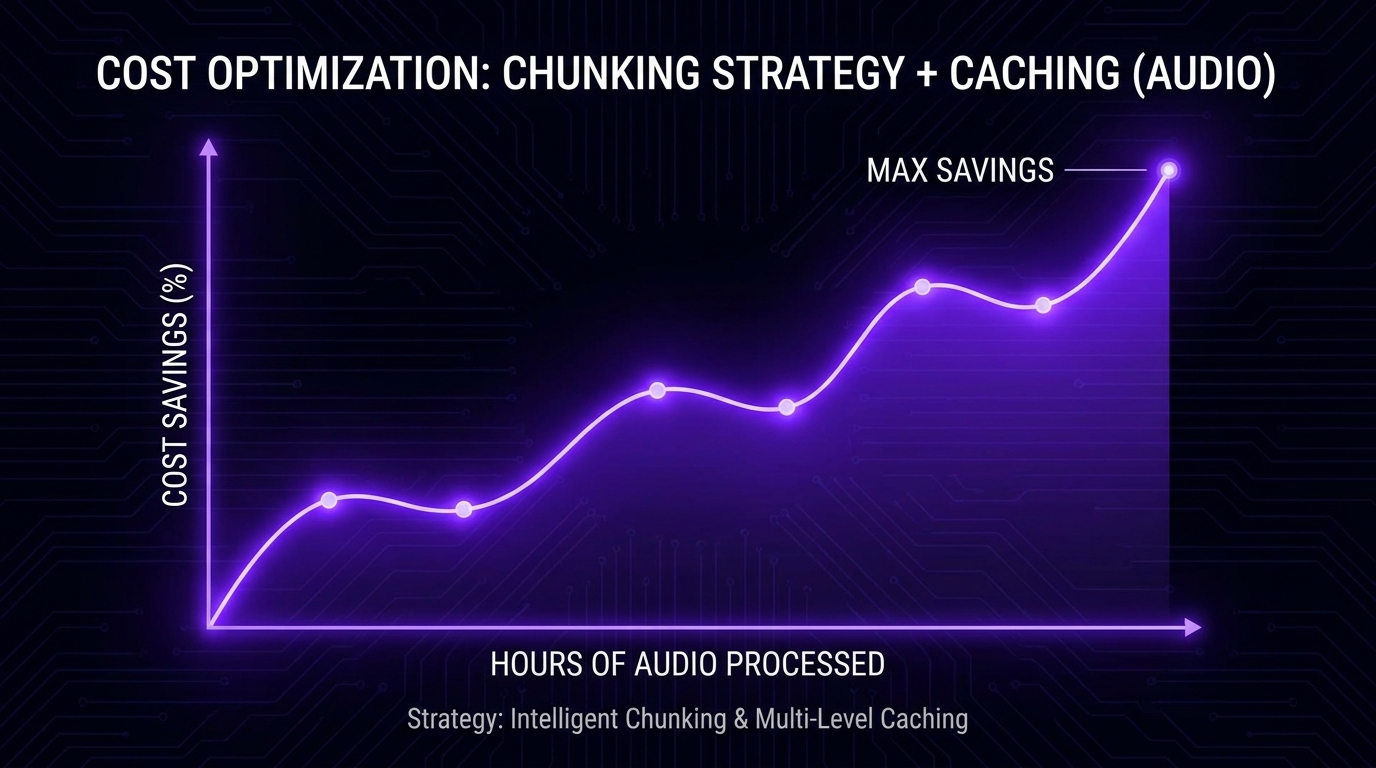
Chi phí pipeline có 3 thành phần: Whisper transcription, Claude inference, infrastructure (storage và bandwidth). Với 100 giờ audio mỗi tháng, công thức gần đúng là Whisper 36 USD (0,006/phút × 6.000 phút), Claude khoảng 20-40 USD tùy model, infra dưới 5 USD. Tổng dao động 60-80 USD/tháng. So với Otter Pro 30 USD/user/month giới hạn 90 phút/lần, hay AssemblyAI add-on stack 0,30 USD/giờ, pipeline tự dựng vẫn rẻ hơn ở scale từ 50 giờ trở lên.
<svg xmlns="http://www.w3.org/2000/svg" viewBox="0 0 640 380" role="img" aria-label="Chi phí pipeline audio theo tháng với optimization stack">
<style>
.ttl{font:600 17px system-ui;fill:#1e1b4b}
.axis{stroke:#6b7280;stroke-width:1}
.lbl{font:500 12px system-ui;fill:#1e1b4b}
.leg{font:500 12px system-ui;fill:#1e1b4b}
.ln1{fill:none;stroke:#312e81;stroke-width:3}
.ln2{fill:none;stroke:#7c3aed;stroke-width:3}
.ln3{fill:none;stroke:#a78bfa;stroke-width:3}
.pt{fill:#1e1b4b}
</style>
<text x="320" y="26" class="ttl" text-anchor="middle">Chi phí 100 giờ audio/tháng (USD) tác động optimization</text>
<line x1="70" y1="320" x2="610" y2="320" class="axis"/>
<line x1="70" y1="60" x2="70" y2="320" class="axis"/>
<text x="60" y="320" class="lbl" text-anchor="end">0</text>
<text x="60" y="270" class="lbl" text-anchor="end">40</text>
<text x="60" y="220" class="lbl" text-anchor="end">80</text>
<text x="60" y="170" class="lbl" text-anchor="end">120</text>
<text x="60" y="120" class="lbl" text-anchor="end">160</text>
<text x="60" y="70" class="lbl" text-anchor="end">200</text>
<text x="120" y="340" class="lbl" text-anchor="middle">T1</text>
<text x="220" y="340" class="lbl" text-anchor="middle">T2</text>
<text x="320" y="340" class="lbl" text-anchor="middle">T3</text>
<text x="420" y="340" class="lbl" text-anchor="middle">T4</text>
<text x="520" y="340" class="lbl" text-anchor="middle">T5</text>
<text x="600" y="340" class="lbl" text-anchor="middle">T6</text>
<polyline class="ln1" points="120,90 220,95 320,100 420,105 520,108 600,110"/>
<polyline class="ln2" points="120,90 220,165 320,200 420,225 520,238 600,245"/>
<polyline class="ln3" points="120,90 220,200 320,245 420,270 520,283 600,290"/>
<g><circle cx="120" cy="90" r="4" class="pt"/><circle cx="220" cy="95" r="4" class="pt"/><circle cx="320" cy="100" r="4" class="pt"/><circle cx="420" cy="105" r="4" class="pt"/><circle cx="520" cy="108" r="4" class="pt"/><circle cx="600" cy="110" r="4" class="pt"/></g>
<g transform="translate(380,75)">
<rect x="0" y="0" width="14" height="3" fill="#312e81"/>
<text x="20" y="6" class="leg">Không optimize (185 USD)</text>
<rect x="0" y="20" width="14" height="3" fill="#7c3aed"/>
<text x="20" y="26" class="leg">Chunking + Whisper API (115 USD)</text>
<rect x="0" y="40" width="14" height="3" fill="#a78bfa"/>
<text x="20" y="46" class="leg">Caching + Batch + Haiku mix (62 USD)</text>
</g>
</svg>
Có 5 đòn bẩy chính giảm chi phí. (1) Prompt caching: Cache transcript khi gọi nhiều task, theo Anthropic cache hit chỉ tốn 10% input price, ROI dương sau 1-2 cache read. (2) Batch API: Giảm 50% input và output token, kết hợp được với prompt caching theo Anthropic docs, đặc biệt phù hợp pipeline xử lý đêm. (3) Model mix: Claude Haiku 4.5 đủ tốt cho summary đơn giản (giá 0,25 USD/M input), Sonnet 4.5 (3 USD/M) cho analysis sâu, Opus chỉ khi cần. (4) Chunking thông minh: Tránh nạp lại context không cần thiết. (5) Whisper local nếu volume cao: Server với GPU 4090 chạy large-v3 đạt 5-7× realtime, hoà vốn so với API ở mức 200 giờ/tháng.
Một sai lầm phổ biến là gọi Whisper trên file gốc dài 60 phút mà không chunk. OpenAI cap upload 25MB và bill theo phút audio thực, nhưng nếu split per speaker turn 8 giây (như AssemblyAI mặc định), bạn 5× billed minutes do minimum 1-2 phút mỗi call. Pattern an toàn: chunk 20 phút overlap 10 giây, mỗi chunk một call, dedupe overlap khi merge transcript.
Citation Capsule: Anthropic Pricing 2026 (Sonnet 3 USD/M, Haiku 0,25 USD/M), Anthropic Batch Processing docs (50% discount), Deepgram Speech-to-Text Pricing 2025, DEV Community 2025 (Whisper minimum minutes pitfall).
Tham khảo thêm Claude Embeddings Vector Search Cho RAG để index và search transcript ở scale lớn.
FAQ
Whisper có chạy được tiếng Việt không? Có. Whisper hỗ trợ chính thức hơn 99 ngôn ngữ trong đó có tiếng Việt. Large-v3 cho WER 12-18% với audio clean tiếng Việt. Nếu bạn cần độ chính xác cao hơn, nên kết hợp pre-processing noise suppression và post-processing bằng Claude.
Pipeline Whisper + Claude khác gì so với gọi Claude trực tiếp? Claude không có speech-to-text built-in, theo Anthropic docs và Vomo 2026, vì cần model chuyên biệt huấn luyện trên giọng nói, tiếng ồn, accent. Pipeline hai tầng cho phép Whisper xử lý phần audio và Claude xử lý phần ngữ nghĩa, mỗi mô hình làm điều mình giỏi nhất.
Bao nhiêu giờ audio mỗi tháng thì đáng dựng pipeline tự? Khoảng 50 giờ trở lên là điểm hoà vốn so với commercial API. Dưới 20 giờ/tháng nên dùng Otter, Fathom hoặc AssemblyAI cho tiện. Từ 50-200 giờ pipeline tự dựng tiết kiệm 30-50%. Trên 500 giờ nên cân nhắc Whisper local trên GPU.
Whisper API và Whisper local khác nhau ở đâu? Whisper API qua OpenAI tính 0,006 USD/phút, không cần GPU, dễ dùng. Whisper local cần GPU 10GB+ VRAM cho large-v3, free về API cost nhưng có chi phí infra. Với volume thấp dùng API, volume cao (500+ giờ/tháng) dùng local. Modal, RunPod cũng có serverless GPU rẻ cho burst.
Có cách nào giảm hallucination Whisper không?
Có ba cách hiệu quả: chunk audio thành đoạn dưới 30 giây nội bộ tránh decoder loop, truyền initial_prompt chứa context, dùng VAD (Voice Activity Detection) như Silero để bỏ silence trước khi transcribe. WhisperX gói sẵn cả ba.
Kết Luận
Combo Whisper + Claude là pipeline xử lý audio tiếng Việt thực tế nhất 2026 cho SME và content creator. Whisper large-v3 đạt WER 12-18% đủ cho phần lớn use case. Claude Sonnet 4.5 với prompt caching và batch API biến transcript thành summary, action items, topic classification với chi phí 0,20-0,36 USD/giờ audio. Bạn cần khoảng 1-2 ngày để dựng pipeline production, ROI dương từ 50 giờ audio/tháng trở lên. Bước tiếp theo: chạy thử trên 5 file audio đại diện của bạn, đo WER thực tế, tính chi phí monthly thực rồi quyết định scale. Nếu bạn muốn xem thêm cách Claude xử lý các loại data khác, hãy đọc tiếp các bài cùng cluster về vision API và embeddings, hoặc xem giải pháp chuyển đổi số tổng thể cho doanh nghiệp Việt.