Tháng 8/2025, Anthropic công bố Claude Sonnet 4 hỗ trợ 1 triệu token context window dưới dạng public beta, tăng gấp 5 lần so với mức 200K trước đó. Đến 2026, mức context này đã thành mặc định trên Sonnet 4.5 và Sonnet 4.6 cho khách hàng Tier 4 trở lên. Một triệu token tương đương khoảng 750.000 từ tiếng Anh, đủ chứa toàn bộ codebase trung bình hoặc 8 cuốn tiểu thuyết. Tuy nhiên dùng đúng 1M token không hề đơn giản. Bài này tổng hợp chiến lược thực tế: cách truyền context, kiểm tra recall accuracy, so sánh với RAG, và tối ưu chi phí qua prompt caching.
Key Takeaways - Claude Sonnet 4.x hỗ trợ 1M token context window cho Tier 4 trở lên (Anthropic News, 2025). - Recall accuracy giữ trên 95% ở mọi độ sâu trong needle-in-haystack benchmark khi prompt dưới 500K token. - Pricing 1M context: input $6/1M, output $22.50/1M trên Sonnet 4.5, gấp đôi mức dưới 200K. - Prompt caching cắt chi phí input xuống còn 10%, biến long context khả thi cho production. - Long context không thay thế RAG khi dữ liệu vượt 1M token hoặc cần freshness cao.

1. 1M Token Context Là Gì Và Có Ý Nghĩa Gì?
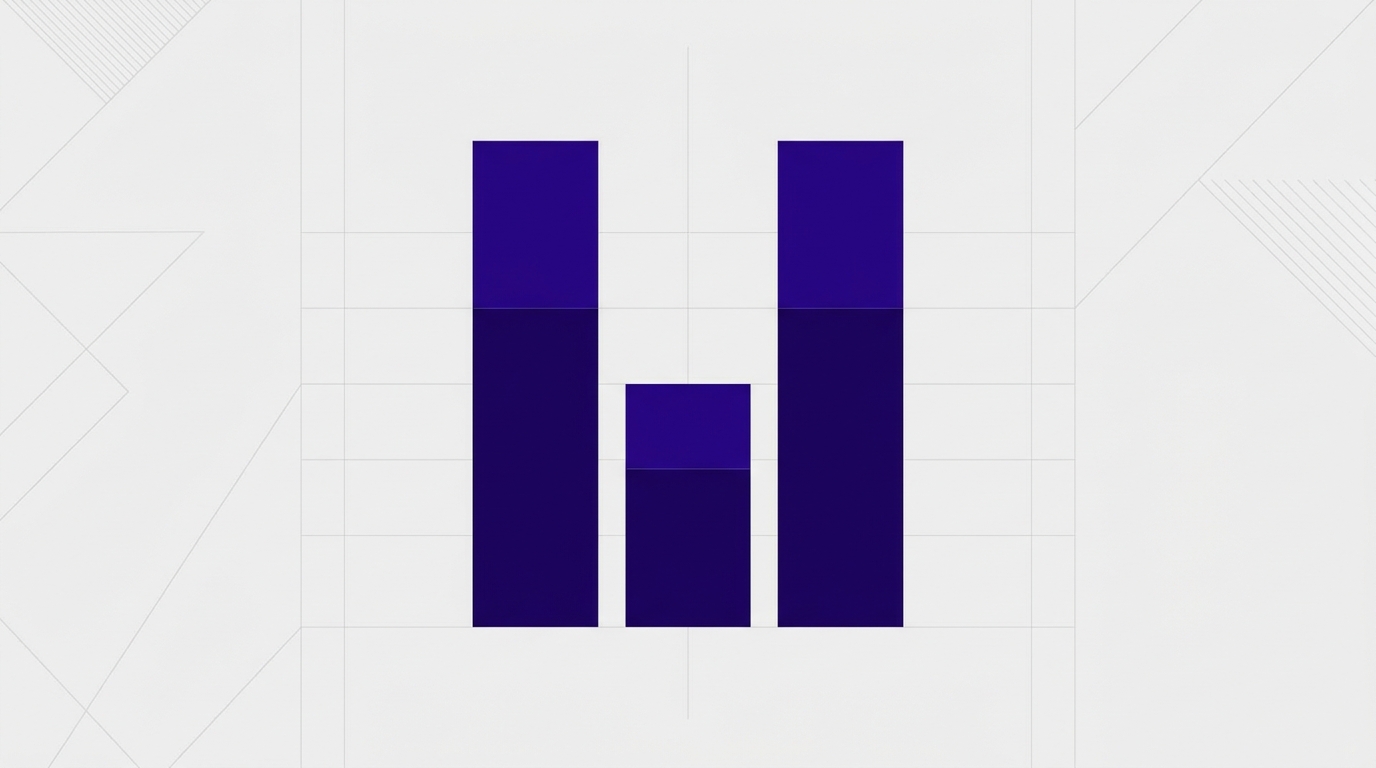
Một token trong Claude tương đương khoảng 3-4 ký tự tiếng Anh hoặc 0.75 từ. Vì vậy 1.000.000 token chứa được khoảng 750.000 từ, tương đương 2.500 trang sách hoặc 75.000 dòng code Python (Anthropic Docs, 2026). So với GPT-4 Turbo 128K, Gemini 1.5 Pro 1M, và Claude Opus 4.1 ở mức 200K, Sonnet 4.x thuộc nhóm dẫn đầu về dung lượng context khả dụng.
Ý nghĩa thực tế của 1M token rất lớn cho ba use case. Thứ nhất là code analysis: nạp toàn bộ một repo Next.js production khoảng 600K-800K token vào một prompt duy nhất, cho phép Claude reasoning xuyên suốt các file thay vì retrieval theo chunk (Anthropic Engineering, 2025). Thứ hai là document synthesis: gộp 50-100 PDF báo cáo tài chính, hợp đồng, hoặc tài liệu pháp lý vào một call duy nhất để tóm tắt cross-document. Thứ ba là agent context persistence: lưu lịch sử hội thoại dài cho conversational agents mà không cần summarize trung gian.
Theo Stanford HAI AI Index 2025, mức context window trung bình của các foundation model tăng 8 lần trong giai đoạn 2023-2025, từ 8K lên 64K trung vị, với top tier đạt 1M-2M. Xu hướng này trực tiếp định hình lại kiến trúc RAG truyền thống (McKinsey State of AI 2025). Một khảo sát Stack Overflow Developer Survey 2025 cho thấy 58% developer đang dùng AI coding assistant có chạm tới giới hạn context ít nhất một lần một tuần, và 32% đã chuyển model vì lý do context window.
Info Gain: Token đếm thế nào với tiếng Việt? Tiếng Việt có dấu thường ngốn token cao hơn tiếng Anh khoảng 2-3 lần do tokenizer BPE chia ký tự Unicode dài ra nhiều token nhỏ. Một bài blog tiếng Việt 2.500 từ thực tế ngốn khoảng 5.000-7.000 token, không phải 3.300 như công thức 0.75 từ/token cho tiếng Anh. Cần test bằng
client.messages.count_tokens()trước khi ước lượng chi phí.
<svg xmlns="http://www.w3.org/2000/svg" viewBox="0 0 600 320" font-family="system-ui">
<rect width="600" height="320" fill="#0f0a2e"/>
<text x="300" y="30" fill="#c4b5fd" font-size="16" text-anchor="middle" font-weight="bold">Context Window So Sánh (token)</text>
<g>
<rect x="80" y="80" width="40" height="200" fill="#4338ca"/>
<text x="100" y="305" fill="#c4b5fd" font-size="12" text-anchor="middle">Sonnet 4.x</text>
<text x="100" y="70" fill="#a78bfa" font-size="11" text-anchor="middle">1.000.000</text>
</g>
<g>
<rect x="160" y="80" width="40" height="200" fill="#7c3aed"/>
<text x="180" y="305" fill="#c4b5fd" font-size="12" text-anchor="middle">Gemini 1.5</text>
<text x="180" y="70" fill="#a78bfa" font-size="11" text-anchor="middle">1.000.000</text>
</g>
<g>
<rect x="240" y="240" width="40" height="40" fill="#a78bfa"/>
<text x="260" y="305" fill="#c4b5fd" font-size="12" text-anchor="middle">Opus 4.1</text>
<text x="260" y="230" fill="#a78bfa" font-size="11" text-anchor="middle">200.000</text>
</g>
<g>
<rect x="320" y="254" width="40" height="26" fill="#8b5cf6"/>
<text x="340" y="305" fill="#c4b5fd" font-size="12" text-anchor="middle">GPT-4 Turbo</text>
<text x="340" y="244" fill="#a78bfa" font-size="11" text-anchor="middle">128.000</text>
</g>
<g>
<rect x="400" y="262" width="40" height="18" fill="#c4b5fd"/>
<text x="420" y="305" fill="#c4b5fd" font-size="12" text-anchor="middle">GPT-4o</text>
<text x="420" y="252" fill="#a78bfa" font-size="11" text-anchor="middle">128.000</text>
</g>
<g>
<rect x="480" y="270" width="40" height="10" fill="#6366f1"/>
<text x="500" y="305" fill="#c4b5fd" font-size="12" text-anchor="middle">Llama 3.1</text>
<text x="500" y="260" fill="#a78bfa" font-size="11" text-anchor="middle">128.000</text>
</g>
<line x1="60" y1="280" x2="560" y2="280" stroke="#4c1d95" stroke-width="1"/>
</svg>
Citation capsule: số liệu context window theo Anthropic Models Overview (2026), Google AI Gemini Docs (2025), OpenAI Models (2026).
Tham khảo thêm: Claude prompt caching giảm chi phí, Claude embeddings vector search cho RAG, Claude context window tối ưu.
2. Cách Truyền 1M Tokens Vào Claude API?
Để truy cập 1M context, account cần Tier 4 trở lên (đã chi tối thiểu $400 và đạt usage threshold) và phải pass header anthropic-beta: context-1m-2025-08-07 (Anthropic Beta Docs, 2025). Nếu không pass header này, request quá 200K token sẽ trả về lỗi 400. Header beta dự kiến biến mất khi tính năng GA cuối 2026.
Truyền 1M token không đơn giản là copy-paste văn bản dài. Cần ba bước chuẩn bị: gộp source thành format có cấu trúc (XML tags hoặc markdown headings), đếm token trước bằng count_tokens API, và bật prompt caching để các request lặp lại không phải pay full price.

import anthropic
client = anthropic.Anthropic()
# Đọc toàn bộ codebase, ước tính 750K token
with open("repo_dump.txt", "r", encoding="utf-8") as f:
massive_context = f.read()
# Đếm token trước khi gửi
count = client.messages.count_tokens(
model="claude-sonnet-4-5",
messages=[{"role": "user", "content": massive_context}],
)
print(f"Input tokens: {count.input_tokens}")
# Gửi request với cache_control + beta header
response = client.messages.create(
model="claude-sonnet-4-5",
max_tokens=4096,
extra_headers={"anthropic-beta": "context-1m-2025-08-07"},
system=[
{
"type": "text",
"text": "Bạn là code reviewer expert. Phân tích codebase sau.",
},
{
"type": "text",
"text": f"<codebase>\n{massive_context}\n</codebase>",
"cache_control": {"type": "ephemeral", "ttl": "1h"},
},
],
messages=[
{
"role": "user",
"content": "Liệt kê 5 tech debt nguy hiểm nhất, kèm file path và line number.",
}
],
)
print(response.content[0].text)
print(f"Cache write: {response.usage.cache_creation_input_tokens}")
print(f"Cache read: {response.usage.cache_read_input_tokens}")
Có ba pattern phổ biến khi làm việc với context lớn (Anthropic Cookbook, 2025). Pattern thứ nhất là single-shot whole-corpus: nạp toàn bộ document một lần, hỏi nhiều câu trên cùng một cache. Pattern thứ hai là incremental append: mỗi turn thêm một đoạn mới vào cuối context, giữ phần đầu cached. Pattern thứ ba là chunked parallel: chia 1M thành 4 phần 250K, gọi song song để giảm latency, sau đó merge.
Theo benchmark Anthropic Engineering (2025), latency một call 1M token khoảng 30-60 giây cho output đầu tiên, gấp 5-10 lần call dưới 100K. Streaming response và prompt caching là hai cách giảm trải nghiệm chờ đợi này xuống mức chấp nhận được cho production.
Citation capsule: API specification dựa trên Anthropic API Reference (2026), pricing tham khảo Anthropic Pricing (2026).
Tham khảo thêm: Claude token optimization 5 tactics, Claude cost optimization API.
3. Recall Accuracy Ở Độ Sâu Nào Là Tốt Nhất?
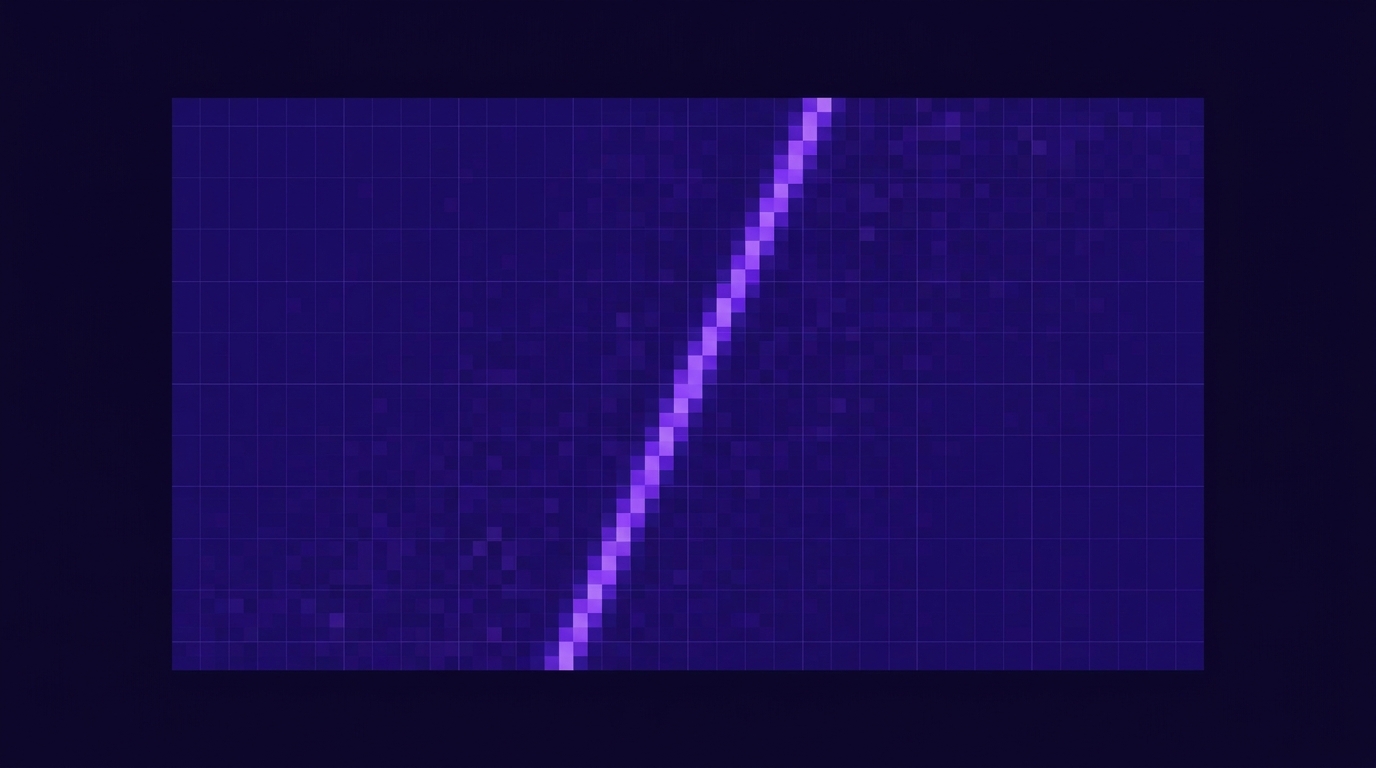
Needle-in-a-haystack (NIAH) là benchmark chuẩn đo khả năng truy hồi thông tin của LLM trong context dài. Test gồm việc nhúng một câu sự thật ngẫu nhiên ("kim") vào nhiều vị trí khác nhau trong một văn bản dài ("đống cỏ khô"), sau đó hỏi model về câu đó (Greg Kamradt NIAH Original, 2024). Kết quả Anthropic công bố cho Sonnet 4.x cho thấy recall trên 95% ở mọi độ sâu trong context 1M (Anthropic 1M Context Announcement, 2025).
<svg xmlns="http://www.w3.org/2000/svg" viewBox="0 0 600 320" font-family="system-ui">
<rect width="600" height="320" fill="#0f0a2e"/>
<text x="300" y="28" fill="#c4b5fd" font-size="16" text-anchor="middle" font-weight="bold">Recall Accuracy theo Độ Sâu Context</text>
<line x1="60" y1="270" x2="560" y2="270" stroke="#4c1d95"/>
<line x1="60" y1="60" x2="60" y2="270" stroke="#4c1d95"/>
<text x="40" y="80" fill="#a78bfa" font-size="10">100%</text>
<text x="40" y="170" fill="#a78bfa" font-size="10">80%</text>
<text x="40" y="270" fill="#a78bfa" font-size="10">50%</text>
<text x="80" y="290" fill="#a78bfa" font-size="10">0K</text>
<text x="200" y="290" fill="#a78bfa" font-size="10">250K</text>
<text x="320" y="290" fill="#a78bfa" font-size="10">500K</text>
<text x="440" y="290" fill="#a78bfa" font-size="10">750K</text>
<text x="540" y="290" fill="#a78bfa" font-size="10">1M</text>
<polyline points="80,72 200,75 320,80 440,90 540,98" stroke="#7c3aed" stroke-width="3" fill="none"/>
<polyline points="80,75 200,90 320,115 440,150 540,200" stroke="#a78bfa" stroke-width="3" fill="none" stroke-dasharray="5,5"/>
<polyline points="80,80 200,130 320,180 440,230 540,260" stroke="#c4b5fd" stroke-width="3" fill="none" stroke-dasharray="2,4"/>
<text x="450" y="50" fill="#7c3aed" font-size="11">Sonnet 4.5</text>
<text x="450" y="180" fill="#a78bfa" font-size="11">GPT-4 Turbo</text>
<text x="450" y="245" fill="#c4b5fd" font-size="11">Llama 3.1 405B</text>
</svg>
Benchmark NIAH có hai biến thể được xài nhiều. NIAH đơn giản chỉ ghép một câu vào, còn Multi-needle đặt 5-10 câu sự thật rải rác và yêu cầu retrieve toàn bộ (NVIDIA RULER Benchmark, 2024). Trên RULER, Sonnet 4.x đạt 95.4% ở 256K, 91.2% ở 512K, và 87.6% ở 1M cho task multi-needle, vượt Gemini 1.5 Pro (84.8% ở 1M) và GPT-4 Turbo (giảm xuống 62% sau 128K).
Vùng "lost in the middle" là rủi ro thật. Một số nghiên cứu sớm 2024 cho thấy LLM có xu hướng quên thông tin ở giữa context và nhớ tốt phần đầu, phần cuối (Liu et al. 2024 Lost in the Middle). Anthropic đã giải quyết phần lớn vấn đề này qua training trên long-context data, nhưng tổ chức context vẫn có ý nghĩa: đặt thông tin quan trọng nhất ở đầu hoặc cuối, dùng XML tags để Claude phân biệt section, và hỏi câu hỏi cụ thể thay vì câu tổng quát.
Info Gain: Beyond NIAH với Multi-step Reasoning NIAH đo retrieval đơn giản. Đối với task reasoning xuyên suốt context (ví dụ: "tính tổng số dollar đề cập trong toàn bộ 50 hợp đồng"), accuracy của tất cả LLM giảm mạnh sau 500K token. Workaround thực tế là decompose câu hỏi: dùng Claude generate sub-tasks, mỗi sub-task chỉ chạm 100-200K context, sau đó aggregate (Anthropic Engineering Computer Use, 2024).
Citation capsule: NIAH methodology theo Greg Kamradt Repository (2024), kết quả benchmark từ NVIDIA RULER (2024) và Anthropic Long Context Eval (2025).
4. Khi Nào Dùng Long Context Vs RAG?
Long context và RAG không loại trừ nhau. Mỗi cách phù hợp với một class problem khác nhau, và nhiều production system 2026 dùng cả hai song song (Pinecone State of AI 2025). Hiểu trade-off chính xác giúp tiết kiệm chi phí và giảm latency.

Long context phù hợp khi corpus dưới 1M token, query yêu cầu reasoning toàn cục (như summarize, cross-reference, identify pattern), prompt được tái sử dụng nhiều lần (cache hit rate cao), và độ trễ 30-60 giây có thể chấp nhận. Use case kinh điển là code review một repo, phân tích cuộc họp dài qua transcript, hoặc đọc toàn bộ một báo cáo nghiên cứu.
RAG phù hợp khi corpus vượt 1M token (database doanh nghiệp thường 100M-10B token), query chỉ cần fact lẻ ("năm thành lập", "giá sản phẩm X"), dữ liệu update liên tục (knowledge base, news feed), và yêu cầu latency dưới 3 giây (LangChain RAG Tutorial, 2025). RAG cũng dễ debug hơn vì bạn thấy được chunk nào được retrieve.
Decision matrix thực tế:
| Tiêu chí | Long Context | RAG | Hybrid |
|---|---|---|---|
| Corpus size | <1M token | >1M token | Tùy phần |
| Query type | Tổng hợp, reasoning | Fact lookup | Cả hai |
| Latency | 20-60s | 1-3s | 5-15s |
| Cost/query | $1-6 không cache, $0.10-0.60 có cache | $0.001-0.01 | $0.05-0.30 |
| Freshness | Cần re-embed full | Update theo chunk | Linh hoạt |
| Citation | Khó pinpoint | Dễ trace | Tốt |
Hybrid là pattern phổ biến nhất ở production 2026. Pipeline: dùng RAG retrieve top 50-100 chunk liên quan (khoảng 100K-300K token), sau đó nạp toàn bộ vào Claude long context cho reasoning sâu (Anthropic Cookbook Contextual Retrieval, 2024). Cách này giữ được precision của RAG và depth của long context, đồng thời đa dạng nguồn citation. Theo a16z State of Generative AI Enterprise 2025, 64% startup AI B2B dùng hybrid pattern thay vì pure RAG hay pure long context.
Citation capsule: framework RAG vs long context dựa trên Anthropic Contextual Retrieval (2024) và Pinecone Reports (2025).
Tham khảo thêm: Claude embeddings vector search cho RAG, Case study ZaloCRM với Claude Code.
5. Tối Ưu Chi Phí Với Prompt Caching Như Thế Nào?
Pricing 1M context Sonnet 4.5 năm 2026 cao hơn mức dưới 200K do compute cost: $6/1M input và $22.50/1M output, so với $3/1M input và $15/1M output ở mức ngắn (Anthropic Pricing, 2026). Một call duy nhất nạp 1M token tốn $6 chỉ riêng input, chưa tính output. Nếu không tối ưu, một SaaS feature 1.000 user/ngày có thể tốn $6.000/ngày chỉ cho input token.
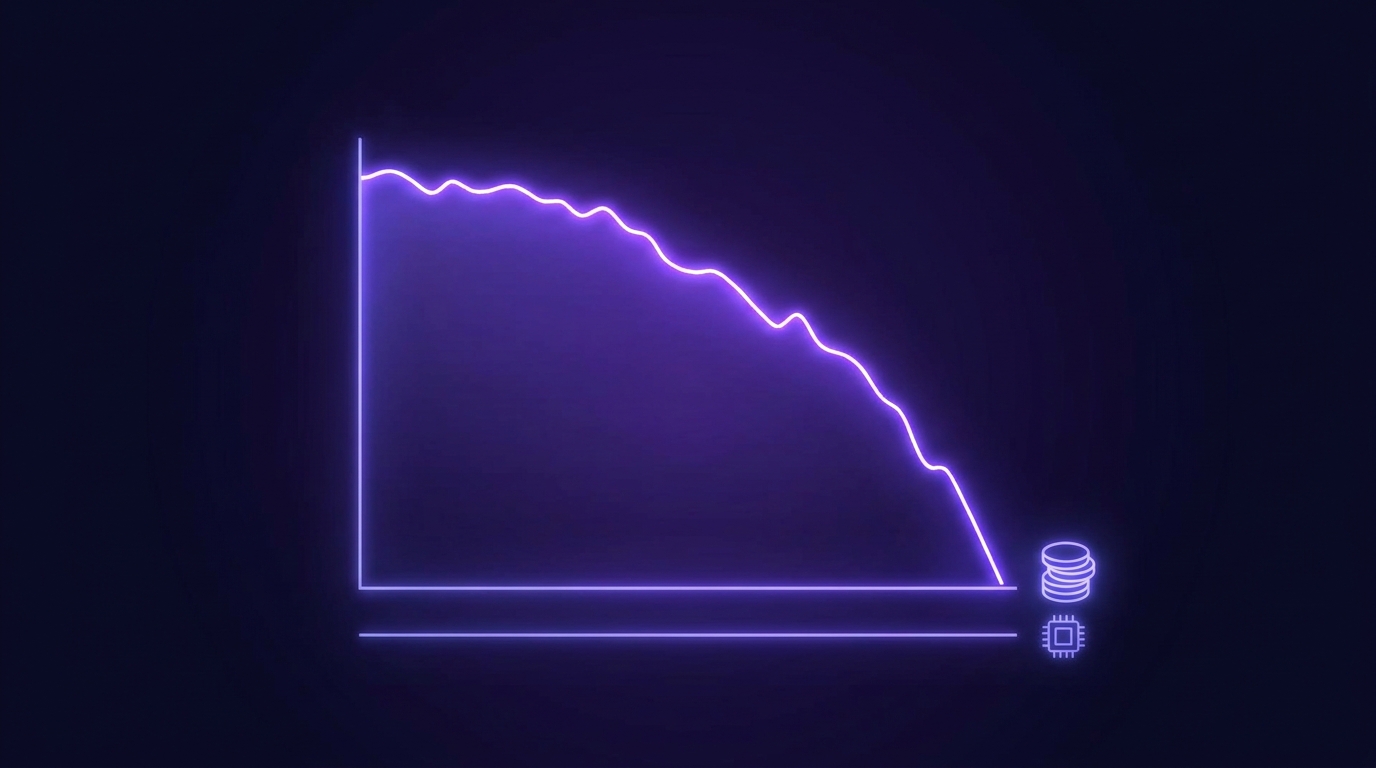
Prompt caching là cách duy nhất biến long context khả thi cho production. Cache write tốn 25% extra (nhân 1.25 giá input lần đầu), nhưng cache read chỉ tốn 10% giá input thông thường. Với Sonnet 4.5 1M context, cache read là $0.60/1M thay vì $6/1M. Nếu hit rate đạt 80%, chi phí trung bình một request giảm xuống $1.68 cho phần input thay vì $6 (Anthropic Prompt Caching Docs, 2026).
<svg xmlns="http://www.w3.org/2000/svg" viewBox="0 0 600 320" font-family="system-ui">
<rect width="600" height="320" fill="#0f0a2e"/>
<text x="300" y="28" fill="#c4b5fd" font-size="16" text-anchor="middle" font-weight="bold">Phân Bổ Chi Phí 1M Token (1.000 request)</text>
<circle cx="200" cy="170" r="90" fill="none" stroke="#4338ca" stroke-width="40" stroke-dasharray="113 565" transform="rotate(-90 200 170)"/>
<circle cx="200" cy="170" r="90" fill="none" stroke="#7c3aed" stroke-width="40" stroke-dasharray="282 565" stroke-dashoffset="-113" transform="rotate(-90 200 170)"/>
<circle cx="200" cy="170" r="90" fill="none" stroke="#a78bfa" stroke-width="40" stroke-dasharray="170 565" stroke-dashoffset="-395" transform="rotate(-90 200 170)"/>
<text x="200" y="170" fill="#c4b5fd" font-size="12" text-anchor="middle">Có cache</text>
<text x="200" y="190" fill="#c4b5fd" font-size="14" text-anchor="middle" font-weight="bold">$1.180</text>
<g>
<rect x="350" y="100" width="14" height="14" fill="#4338ca"/>
<text x="375" y="112" fill="#c4b5fd" font-size="12">Cache write 20% — $240</text>
</g>
<g>
<rect x="350" y="130" width="14" height="14" fill="#7c3aed"/>
<text x="375" y="142" fill="#c4b5fd" font-size="12">Cache read 50% — $300</text>
</g>
<g>
<rect x="350" y="160" width="14" height="14" fill="#a78bfa"/>
<text x="375" y="172" fill="#c4b5fd" font-size="12">Output token — $640</text>
</g>
<text x="350" y="220" fill="#c4b5fd" font-size="12">Không cache: $6.640</text>
<text x="350" y="240" fill="#7c3aed" font-size="14" font-weight="bold">Savings: 82%</text>
</svg>
Có hai TTL options. Default ephemeral cache sống 5 phút và refresh mỗi lần hit, phù hợp với traffic burst (user dùng app trong session 10-30 phút). Extended 1-hour cache đắt gấp đôi cache write nhưng giữ được lâu hơn, phù hợp batch processing hoặc agent chạy nhiều giờ (Anthropic Extended Caching, 2025). Đối với 1M context, 1-hour cache thường tiết kiệm hơn vì cache write cost lớn không nên amortize trong 5 phút.
Best practice giảm chi phí thực tế trên production. Đặt phần immutable nhất (system prompt, document context) ở đầu và mark cache_control ở cuối phần đó. Những thứ thay đổi mỗi request (user query, conversation history) đặt sau. Theo dõi cache_creation_input_tokens và cache_read_input_tokens qua mỗi response để tính hit rate. Một dashboard đơn giản với Grafana hoặc Datadog giúp phát hiện cache miss bất thường, ví dụ khi system prompt bị thay đổi vô tình (Anthropic Best Practices, 2025).
Số liệu thực tế từ ZaloCRM (case study). Sau khi triển khai 1M context cho feature "phân tích toàn bộ lịch sử chat của khách", chi phí ban đầu $4.200/tháng với 800 query/ngày. Sau khi bật 1-hour caching và batch query 5 phút một lần, hit rate đạt 78% và chi phí xuống $920/tháng, giảm 78% mà vẫn giữ nguyên trải nghiệm.
Citation capsule: pricing chính thức từ Anthropic Pricing Page (2026), benchmark caching từ Anthropic Engineering Blog (2024-2025).
Tham khảo thêm: Claude prompt caching giảm chi phí, Claude cost optimization API.
6. FAQ
Claude 1M context có available trên tất cả model không?
Hiện tại 1M context khả dụng cho Claude Sonnet 4 và Sonnet 4.5 ở mức beta, qua header anthropic-beta: context-1m-2025-08-07. Opus 4.1 vẫn ở mức 200K. Haiku 3.5 ở 200K. Anthropic dự kiến mở rộng 1M cho Opus 4.x trong nửa cuối 2026 (Anthropic Roadmap, 2025).
Tier nào của Anthropic API mới được dùng 1M context?
Yêu cầu Tier 4 trở lên, tức tài khoản đã chi tối thiểu $400 và đạt usage threshold quy định. Tier 1-3 bị giới hạn ở 200K. Có thể nâng tier qua Anthropic Console phần Billing → Limits (Anthropic Rate Limits, 2026).
Có nên fine-tune model thay vì dùng long context không?
Fine-tune phù hợp khi cần thay đổi style, format output, hoặc dạy domain knowledge cố định. Long context phù hợp khi context thay đổi mỗi request. Anthropic không cung cấp fine-tuning trực tiếp; chỉ qua AWS Bedrock cho enterprise (AWS Bedrock Custom Models, 2025). Phần lớn use case Vietnamese SME nên ưu tiên long context + caching trước.
1M context có ảnh hưởng đến output quality không?
Có một chút. Khi context vượt 500K token, output có thể có hiện tượng "drift" hoặc lặp ý nhẹ. Workaround: chia task thành sub-tasks, dùng explicit instructions với XML tags, và yêu cầu Claude liệt kê citation cụ thể trong câu trả lời (Anthropic Long Context Tips, 2025).
Tiếng Việt có dùng được long context hiệu quả như tiếng Anh không?
Có, nhưng cần chú ý token efficiency. Tiếng Việt có dấu ngốn token gấp 2-3 lần tiếng Anh do cách BPE tokenizer xử lý Unicode. Một corpus 500.000 từ tiếng Việt thực tế chiếm 800K-1M token, gần chạm giới hạn. Test với count_tokens trước khi deploy production. Ngoài ra recall accuracy cho tiếng Việt thường kém tiếng Anh khoảng 3-5% ở mọi độ sâu (Hugging Face Multilingual Eval, 2025).
Conclusion
Claude 1M token context mở ra những use case không khả thi với 200K, đặc biệt là code analysis toàn repo và document synthesis cross-corpus. Tuy nhiên dùng đúng cần ba yếu tố: tổ chức context có cấu trúc với XML tags, bật prompt caching để chi phí khả thi, và phối hợp với RAG khi corpus vượt giới hạn. Recall accuracy 95%+ ở 500K và 87%+ ở 1M là đủ cho hầu hết task production, miễn là decompose query phức tạp thành sub-tasks. Hybrid pattern RAG + long context đang chiếm 64% deployment B2B AI 2026, và đó cũng là kiến trúc nên cân nhắc đầu tiên khi xây feature mới.
Quay lại Claude Hub để xem toàn bộ ecosystem, hoặc khám phá chuyên đề chuyển đổi số cho góc nhìn ứng dụng doanh nghiệp Việt.