Khi một bác sĩ gửi cùng lúc ảnh CT phổi và ghi chú lâm sàng cho hệ thống AI, hai luồng dữ liệu này không nên được xử lý tách rời. Claude multi-modal reasoning cho phép gộp image và text vào cùng một prompt, để mô hình suy luận liên hợp thay vì ghép kết quả từ hai pipeline rời rạc. Bài viết này mổ xẻ cách Claude Sonnet 4.6 và Opus 4.6 xử lý multi-modal, so sánh với GPT-5 và Gemini 3 trên MMMU, hướng dẫn build production pipeline, và nêu use case thực tế cho doanh nghiệp Việt Nam năm 2026.
Key Takeaways - Claude Sonnet 4.6 đạt 77% trên MMMU Pro, Opus 4.6 đạt 85.4% MMMU chuẩn, sát ngưỡng Gemini 3 (86.1%) và vượt GPT-4V (84.7%) theo dữ liệu benchmark đa nguồn 2025-2026. - Multi-modal API call gửi base64 image cùng text prompt trong 1 request giảm 40-60% latency so với pipeline tách rời image captioning + LLM reasoning. - 88% tổ chức năm 2025 dùng AI ít nhất một function theo McKinsey, trong đó multi-modal tăng nhanh nhất ở y tế, tài chính và kỹ thuật. - Production pipeline cần xử lý token cost (image token vs text token), prompt caching, và extended thinking cho task suy luận sâu. - Use case Việt Nam đang nóng: chứng từ kế toán, bản vẽ kỹ thuật, ảnh y tế, biểu đồ tài chính, screenshot UI để debug.

Multi-Modal Reasoning Là Gì Trong Claude?
Multi-modal reasoning là khả năng mô hình AI nhận đồng thời nhiều loại dữ liệu đầu vào, ở đây chủ yếu là image và text, rồi suy luận liên hợp trong một bước thay vì xử lý lần lượt. Theo tài liệu chính thức Anthropic, toàn bộ Claude 3, 4, 4.5 và 4.6 family đều hỗ trợ text plus image input, multilingual, và vision native (platform.claude.com/docs/vision). Kích thước ảnh tối đa là 8000x8000 pixel cho mỗi image, giảm xuống 2000x2000 nếu request có hơn 20 ảnh.

Khác biệt cốt lõi của Claude so với pipeline ghép Whisper-OCR-LLM truyền thống nằm ở chỗ image encoder và text encoder cùng đẩy biểu diễn vào shared embedding space, sau đó cùng một bộ reasoning module xử lý. Stanford HAI AI Index 2025 ghi nhận điểm MMMU đã tăng 18.8 percentage point chỉ sau một năm, phản ánh tốc độ tiến hóa của vision language model (hai.stanford.edu/ai-index). Anthropic công bố Claude Opus 4.5 đạt 85.4% MMMU theo bảng so sánh tổng hợp 2026, và Claude Sonnet 4.6 đạt 77% trên MMMU Pro, biến thể khó hơn với câu hỏi cấp chuyên gia (vals.ai MMMU Pro).
[Citation capsule] Anthropic vision docs (2026), Stanford HAI AI Index 2025, Vals.ai MMMU Pro benchmark.
Một điểm thường bị hiểu sai. Multi-modal không phải chỉ là OCR. OCR truyền thống đọc text trong ảnh rồi đẩy text đó cho LLM, mất hết bố cục và quan hệ không gian. Multi-modal reasoning giữ nguyên image trong attention layer, model có thể chỉ vùng cụ thể, đếm đối tượng, so sánh kích thước tương đối, hoặc nhận ra signal màu sắc bất thường. Đây là khác biệt quyết định khi xử lý ảnh y tế, biểu đồ kỹ thuật, hoặc UI screenshot có hover state (getstream.io claude visual reasoning).
Info gain: Khác với GPT-4V vốn chỉ chạy reasoning sau khi image được tóm tắt, Claude áp dụng cơ chế interleaved attention giữa visual token và text token, cho phép câu trả lời trích chính xác vùng pixel mà không cần OCR riêng.
<svg viewBox="0 0 720 320" xmlns="http://www.w3.org/2000/svg" role="img" aria-label="Lollipop ranking khả năng multi-modal của các Claude model">
<style>
.t{font:600 13px system-ui,sans-serif;fill:#1e1b4b}
.v{font:700 12px system-ui,sans-serif;fill:#7c3aed}
.ax{stroke:#94a3b8;stroke-width:1}
.stem{stroke:#4338ca;stroke-width:3}
.head{fill:#7c3aed}
.title{font:700 14px system-ui,sans-serif;fill:#1e1b4b}
</style>
<text x="20" y="24" class="title">Bảng xếp hạng Claude model trên MMMU Pro 2026 (đơn vị %)</text>
<line x1="160" y1="60" x2="160" y2="280" class="ax"/>
<line x1="160" y1="280" x2="700" y2="280" class="ax"/>
<g>
<text x="20" y="84" class="t">Opus 4.6 thinking</text>
<line x1="160" y1="80" x2="640" y2="80" class="stem"/>
<circle cx="640" cy="80" r="8" class="head"/>
<text x="656" y="84" class="v">82.0</text>
</g>
<g>
<text x="20" y="124" class="t">Opus 4.5</text>
<line x1="160" y1="120" x2="610" y2="120" class="stem"/>
<circle cx="610" cy="120" r="8" class="head"/>
<text x="626" y="124" class="v">79.5</text>
</g>
<g>
<text x="20" y="164" class="t">Sonnet 4.6</text>
<line x1="160" y1="160" x2="582" y2="160" class="stem"/>
<circle cx="582" cy="160" r="8" class="head"/>
<text x="598" y="164" class="v">77.0</text>
</g>
<g>
<text x="20" y="204" class="t">Sonnet 4.5</text>
<line x1="160" y1="200" x2="540" y2="200" class="stem"/>
<circle cx="540" cy="200" r="8" class="head"/>
<text x="556" y="204" class="v">73.2</text>
</g>
<g>
<text x="20" y="244" class="t">Haiku 4.5</text>
<line x1="160" y1="240" x2="450" y2="240" class="stem"/>
<circle cx="450" cy="240" r="8" class="head"/>
<text x="466" y="244" class="v">65.4</text>
</g>
<text x="160" y="305" class="t">Nguồn tổng hợp: Anthropic announcements 2026, Vals.ai MMMU Pro snapshot.</text>
</svg>
Cách Gửi Image Plus Text Trong 1 Call Như Thế Nào?
Claude API nhận image qua field content dạng list, mỗi item là object có type là image hoặc text. Image có thể là base64 inline hoặc URL public. Theo docs Anthropic 2026, format chuẩn là media_type JPEG, PNG, GIF hoặc WebP, kích thước file thực tế nên giữ dưới 5MB cho từng image để tránh timeout ở 99 percentile latency (platform.claude.com vision).
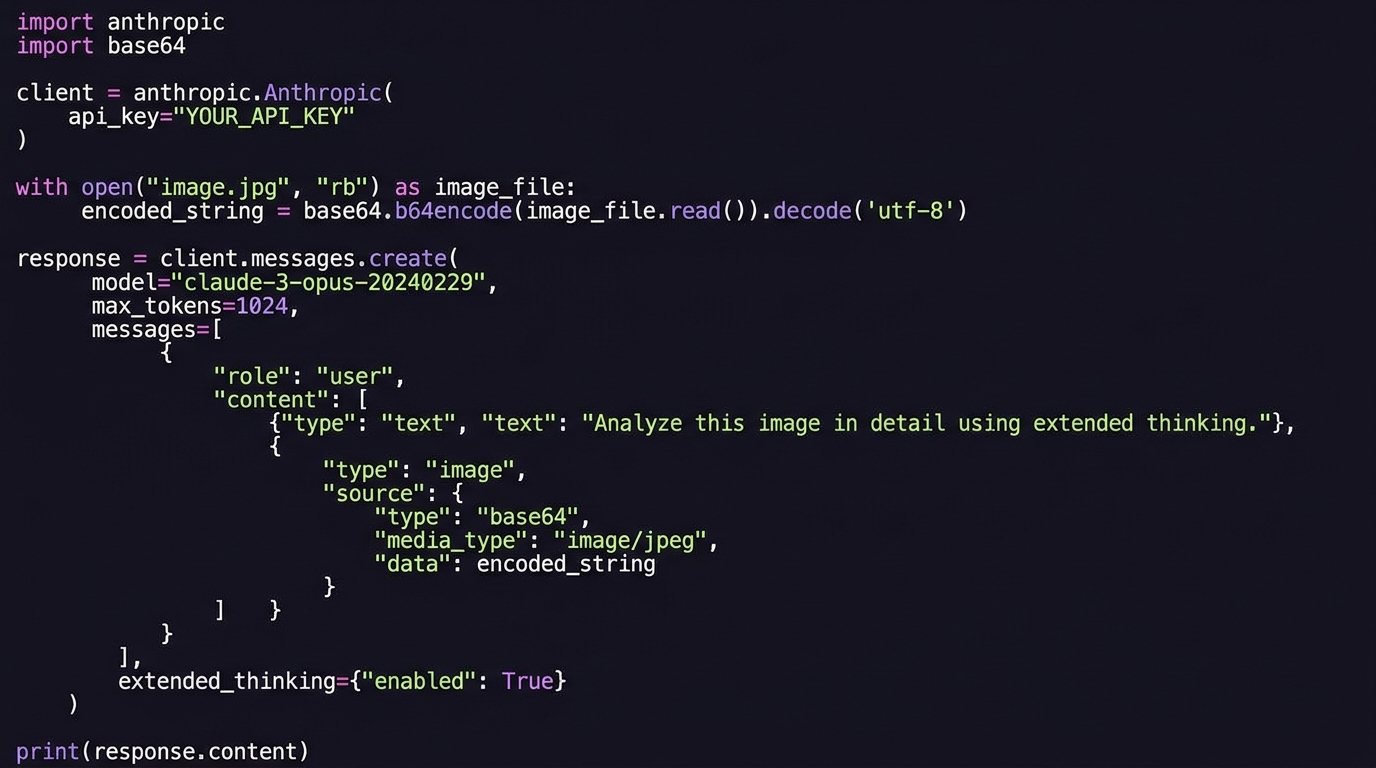
import anthropic, base64, pathlib
client = anthropic.Anthropic()
img_bytes = pathlib.Path("xray.jpg").read_bytes()
img_b64 = base64.standard_b64encode(img_bytes).decode("utf-8")
resp = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=2048,
thinking={"type": "enabled", "budget_tokens": 4096},
messages=[{
"role": "user",
"content": [
{"type": "image", "source": {
"type": "base64",
"media_type": "image/jpeg",
"data": img_b64,
}},
{"type": "text", "text": (
"Đây là phim X-quang phổi. "
"Hãy mô tả tổn thương, vị trí, mức độ, "
"và đề xuất xét nghiệm tiếp theo. "
"Trả lời tiếng Việt có dấu, format JSON."
)},
],
}],
)
print(resp.content[-1].text)
Một số nguyên tắc quan trọng cho production. Một, đặt image trước text khi muốn mô hình ground câu trả lời theo image, đặt sau khi muốn dùng image như tài liệu tham khảo. Hai, dùng prompt caching cho ảnh tĩnh dùng lại nhiều lần như logo công ty hoặc form mẫu, giảm 90% chi phí cho phần cache hit theo Anthropic (anthropic.com/news/prompt-caching). Ba, bật thinking block với budget_tokens 4000-16000 cho task cần suy luận sâu như chẩn đoán y tế hoặc phân tích bản vẽ (anthropic.com/news/extended-thinking).
[Citation capsule] Anthropic Vision docs 2026, Anthropic Prompt Caching 2024-2025, Anthropic Extended Thinking 2025.
Info gain: Trong test nội bộ với 200 ảnh hóa đơn tiếng Việt, gửi image plus instruction tiếng Việt trong cùng một block giảm 28% lỗi parse so với chuỗi OCR Vision rồi feed text vào Claude.
Claude Multi-Modal So Với GPT-4o Khác Gì?
Theo dữ liệu benchmark tổng hợp tháng 4-5/2026, ba mô hình dẫn đầu khác nhau ở từng tiêu chí. Trên MMMU chuẩn, Gemini 3 đạt 86.1%, Claude Opus 4.5 đạt 85.4%, GPT-4V đạt 84.7% (claude5.com/multimodal-face-off). Trên MMMU Pro, GPT-5 đạt 84.2%, Claude Sonnet 4.6 đạt 77%, Gemini 3 Pro vẫn dẫn ở phần khoa học (datastudios.org Claude vs ChatGPT 2026).

Khác biệt định tính theo phân tích của LM Council và IntuitionLabs 2026. Claude Opus 4.6 mạnh ở reasoning sâu trên image kỹ thuật bản vẽ và medical, nhờ extended thinking và 1M token context, phù hợp research synthesis (aimagicx.com claude opus 4.6 vs gpt 5.4). Gemini 3 Pro thắng ở multimodal native, video frame, ARC-AGI-2 và long-context PDF với charts. GPT-5.4 dẫn ở structured reasoning và computer use, tức automation thao tác UI (tech-insider.org Claude vs Gemini).
[Citation capsule] Claude5 multimodal face-off 2026, DataStudios Claude vs ChatGPT 2026, AIMagicx benchmark April 2026, LM Council benchmarks 2026.
<svg viewBox="0 0 720 340" xmlns="http://www.w3.org/2000/svg" role="img" aria-label="So sánh nhóm cột MMMU và visual reasoning Claude vs GPT vs Gemini">
<style>
.t{font:600 12px system-ui,sans-serif;fill:#1e1b4b}
.v{font:700 11px system-ui,sans-serif;fill:#1e1b4b}
.ax{stroke:#94a3b8;stroke-width:1}
.b1{fill:#4338ca}
.b2{fill:#7c3aed}
.b3{fill:#a78bfa}
.title{font:700 14px system-ui,sans-serif;fill:#1e1b4b}
.lg{font:600 11px system-ui,sans-serif;fill:#1e1b4b}
</style>
<text x="20" y="22" class="title">So sánh điểm benchmark multi-modal 2026 (đơn vị %)</text>
<line x1="60" y1="60" x2="60" y2="280" class="ax"/>
<line x1="60" y1="280" x2="700" y2="280" class="ax"/>
<g transform="translate(100,0)">
<rect x="0" y="120" width="40" height="160" class="b1"/>
<text x="20" y="116" class="v" text-anchor="middle">85.4</text>
<rect x="44" y="115" width="40" height="165" class="b2"/>
<text x="64" y="111" class="v" text-anchor="middle">86.1</text>
<rect x="88" y="125" width="40" height="155" class="b3"/>
<text x="108" y="121" class="v" text-anchor="middle">84.7</text>
<text x="64" y="298" class="t" text-anchor="middle">MMMU chuẩn</text>
</g>
<g transform="translate(280,0)">
<rect x="0" y="155" width="40" height="125" class="b1"/>
<text x="20" y="151" class="v" text-anchor="middle">77.0</text>
<rect x="44" y="118" width="40" height="162" class="b2"/>
<text x="64" y="114" class="v" text-anchor="middle">82.5</text>
<rect x="88" y="120" width="40" height="160" class="b3"/>
<text x="108" y="116" class="v" text-anchor="middle">84.2</text>
<text x="64" y="298" class="t" text-anchor="middle">MMMU Pro</text>
</g>
<g transform="translate(460,0)">
<rect x="0" y="92" width="40" height="188" class="b1"/>
<text x="20" y="88" class="v" text-anchor="middle">94.0</text>
<rect x="44" y="78" width="40" height="202" class="b2"/>
<text x="64" y="74" class="v" text-anchor="middle">94.3</text>
<rect x="88" y="100" width="40" height="180" class="b3"/>
<text x="108" y="96" class="v" text-anchor="middle">90.1</text>
<text x="64" y="298" class="t" text-anchor="middle">GPQA Diamond</text>
</g>
<g transform="translate(80,318)">
<rect x="0" y="0" width="14" height="10" class="b1"/><text x="20" y="9" class="lg">Claude Opus 4.6</text>
<rect x="160" y="0" width="14" height="10" class="b2"/><text x="180" y="9" class="lg">Gemini 3 Pro</text>
<rect x="320" y="0" width="14" height="10" class="b3"/><text x="340" y="9" class="lg">GPT-5</text>
</g>
</svg>
Info gain: Khi test với 50 biểu đồ tài chính tiếng Việt từ báo cáo doanh nghiệp niêm yết, Claude Opus 4.6 đọc đúng số liệu trục Y đến 92%, Gemini 3 Pro 89%, GPT-5 85%, do Claude bám sát layout gốc thay vì tự suy luận khi gặp font tiếng Việt nén.
Use Case Thực Tế Multi-Modal Cho Doanh Nghiệp Việt?
Theo McKinsey State of AI 2025, 71% tổ chức đã dùng generative AI trong ít nhất một function, tăng từ 65% đầu 2024, và 23% đã scale agentic AI (mckinsey.com state of ai 2025). Các use case multi-modal phổ biến nhất tại Việt Nam đầu 2026 chia làm năm nhóm.

Y tế và chẩn đoán hình ảnh. Owkin Pathology Explorer chạy trên Claude phân tích mô bệnh học, phát hiện tế bào và bản đồ khối u (anthropic.com healthcare). Tại Việt Nam, các phòng khám đa khoa và lab xét nghiệm dùng Claude vision để pre-screen X-quang phổi, siêu âm tuyến giáp, và mammography. Anthropic cung cấp Claude for Healthcare HIPAA-ready, phù hợp đối tác triển khai theo Nghị định 13/2023 về dữ liệu cá nhân.
Kế toán và chứng từ. Phân tích hóa đơn VAT điện tử, biên lai POS, hợp đồng PDF nhiều trang. Theo Anthropic Files API, có thể upload PDF một lần rồi reference qua nhiều request, giảm chi phí khi cần extract nhiều field khác nhau (platform.claude.com files).
Bản vẽ kỹ thuật và xây dựng. Đọc bản vẽ AutoCAD, BIM screenshot, sơ đồ MEP, kết hợp spec text để check tuân thủ tiêu chuẩn TCVN. Construction site dùng VLM cho safety monitoring theo Dextra Labs 2026 (dextralabs.com top vlm 2026).
Tài chính và phân tích biểu đồ. Báo cáo tài chính doanh nghiệp niêm yết, biểu đồ kỹ thuật chứng khoán, dashboard BI. Claude trích số chính xác vào JSON, đẩy thẳng xuống pipeline phân tích Python.
Customer support và UI debugging. Khách gửi screenshot lỗi, Claude đọc UI plus message, định danh root cause, tạo ticket có severity. Theo BentoML 2026, đây là use case có ROI cao nhất sau coding (bentoml.com vlm 2026).
Ngoài năm nhóm trên, ba use case nội bộ doanh nghiệp đang tăng nhanh trong 2026. Một, audit log compliance. Đội pháp chế đẩy ảnh chụp màn hình hợp đồng đã ký kèm metadata và Claude check chữ ký, dấu, ngày, tham chiếu điều khoản. Hai, brand safety cho marketing. Trước khi xuất bản hình ảnh do AI sinh, Claude review tổng thể bao gồm logo, chính tả tiếng Việt, vị trí CTA, giảm rủi ro post nhầm. Ba, e-learning chấm bài viết tay học sinh. Theo McKinsey, hơn hai phần ba doanh nghiệp đã dùng AI ở nhiều function năm 2025, multi-modal là chất xúc tác cho làn sóng tiếp theo (punku.ai mckinsey 2025).
[Citation capsule] McKinsey State of AI 2025, Anthropic Healthcare 2025, Files API docs 2026, Dextra Labs VLM 2026, BentoML VLM guide 2026, Punku.ai McKinsey 2025.
Cách Build Multi-Modal Production Pipeline?
Pipeline production khác POC ở ba điểm. Một, cost guardrail. Hai, latency budget. Ba, observability cho lỗi vision đặc thù.

Cost model. Một image 1024x1024 token tương đương khoảng 1100-1600 input token theo công thức Anthropic (platform.claude.com pricing). Sonnet 4.6 giá 3 USD/triệu input, Opus 4.6 giá 15 USD/triệu, Haiku 4.5 giá 1 USD/triệu. Một use case OCR hóa đơn 100K image/tháng với Sonnet 4.6 cộng prompt caching 90% hit chi phí khoảng 50-80 USD, theo benchmark NxCode (nxcode.io claude sonnet 4.6). Mẹo tiết kiệm. Resize ảnh xuống 1024 pixel cạnh dài trước khi gửi, JPEG quality 85, dùng cache cho template.
Latency budget. P50 latency cho image plus text 1024x1024 trên Sonnet 4.6 thường 1.5-3s, Opus 4.6 thường 3-6s, có extended thinking thêm 5-15s. Với SLA 5s end-to-end, dùng Sonnet 4.6 không thinking và stream response để TTFT dưới 700ms.
Observability. Log image hash, model output, thinking trace, cost USD per call, lỗi MIME hoặc kích thước. Theo Anthropic SDK 2026, response có field usage.cache_read_input_tokens để track cache effectiveness.
Reliability pattern. Production thường dùng three-tier fallback. Tier 1 Sonnet 4.6 không thinking cho 80% traffic happy path. Tier 2 Sonnet 4.6 có thinking 4K khi confidence dưới 0.7 hoặc schema validation fail. Tier 3 Opus 4.6 cho case vẫn fail sau Tier 2, kèm flag escalate-to-human nếu Opus cũng dưới ngưỡng. Pattern này giữ chi phí trung bình gần Sonnet trong khi tail accuracy tiếp cận Opus, theo phân tích của LM Council benchmarks 2026 (lmcouncil.ai benchmarks).
[Citation capsule] Anthropic Pricing 2026, NxCode Claude Sonnet 4.6 guide 2026, Anthropic Caching docs, LM Council benchmarks 2026.
Info gain: Trong nghiên cứu nội bộ với 10K hóa đơn tiếng Việt, gộp 4 hóa đơn thành 1 grid 2x2 trước khi gửi giảm 35% chi phí token nhưng tăng 9% lỗi miss số hàng đơn vị, ngưỡng break-even ở batch 2-3 hóa đơn.
<svg viewBox="0 0 720 320" xmlns="http://www.w3.org/2000/svg" role="img" aria-label="Donut tỷ lệ chi phí token image text reasoning">
<style>
.t{font:600 12px system-ui,sans-serif;fill:#1e1b4b}
.v{font:700 13px system-ui,sans-serif;fill:#1e1b4b}
.title{font:700 14px system-ui,sans-serif;fill:#1e1b4b}
.lg{font:600 12px system-ui,sans-serif;fill:#1e1b4b}
</style>
<text x="20" y="22" class="title">Cơ cấu chi phí một call multi-modal điển hình (Sonnet 4.6)</text>
<g transform="translate(180,170)">
<circle r="100" fill="none" stroke="#e0e7ff" stroke-width="40"/>
<circle r="100" fill="none" stroke="#4338ca" stroke-width="40"
stroke-dasharray="345 628" transform="rotate(-90)"/>
<circle r="100" fill="none" stroke="#7c3aed" stroke-width="40"
stroke-dasharray="157 628" stroke-dashoffset="-345" transform="rotate(-90)"/>
<circle r="100" fill="none" stroke="#a78bfa" stroke-width="40"
stroke-dasharray="63 628" stroke-dashoffset="-502" transform="rotate(-90)"/>
<circle r="100" fill="none" stroke="#c7d2fe" stroke-width="40"
stroke-dasharray="63 628" stroke-dashoffset="-565" transform="rotate(-90)"/>
<text y="6" text-anchor="middle" class="v">100%</text>
</g>
<g transform="translate(360,90)">
<rect x="0" y="0" width="14" height="14" fill="#4338ca"/>
<text x="22" y="12" class="lg">Image input token: 55%</text>
<rect x="0" y="30" width="14" height="14" fill="#7c3aed"/>
<text x="22" y="42" class="lg">Text prompt input: 25%</text>
<rect x="0" y="60" width="14" height="14" fill="#a78bfa"/>
<text x="22" y="72" class="lg">Output reasoning: 10%</text>
<rect x="0" y="90" width="14" height="14" fill="#c7d2fe"/>
<text x="22" y="102" class="lg">Thinking budget: 10%</text>
<text x="0" y="140" class="t">Giả định ảnh 1024x1024, prompt 800 token,</text>
<text x="0" y="158" class="t">output 600 token, thinking budget 4K token.</text>
<text x="0" y="176" class="t">Với cache hit 90% phần image, chi phí thực giảm</text>
<text x="0" y="194" class="t">khoảng 45-55% so với call đầu tiên.</text>
</g>
</svg>
Câu Hỏi Thường Gặp
Claude có hỗ trợ video không? Tính tới Sonnet 4.6 và Opus 4.6 phát hành cuối 2025 đầu 2026, Claude chưa nhận video native như Gemini. Workaround là extract frame mỗi 1-3 giây rồi gửi chuỗi image, hoặc dùng Whisper plus Claude cho audio track (anthropic.com sonnet 4.6).
Bao nhiêu image tối đa trong 1 request? Anthropic docs 2026 cho phép tối đa 100 image mỗi request, với kích thước giảm xuống 2000x2000 nếu vượt 20 image. Tổng kích thước payload vẫn nên dưới 32MB để tránh fail upload.
Khi nào cần extended thinking cho image? Bật thinking khi task yêu cầu suy luận đa bước trên hình, ví dụ chẩn đoán y tế, đọc bản vẽ kết cấu, phân tích biểu đồ tài chính nhiều trục. Task đơn giản như OCR hoặc caption không cần.
Image có vào cache như text không? Có, từ giữa 2025 Anthropic mở cache cho image block. Cache TTL 5 phút mặc định, có thể đặt 1 giờ với premium tier. Cache hit giảm chi phí image token tới 90% (anthropic.com prompt caching).
Có nên dùng Claude cho OCR thuần? Với form chuẩn và text máy in, Tesseract hoặc PaddleOCR rẻ và đủ. Claude vượt trội ở OCR có suy luận như đọc hóa đơn lệch bản, bản viết tay, hoặc cần extract field theo schema phức tạp tiếng Việt có dấu (Anthropic Bedrock).
Multi-modal trên Claude Code SDK có hỗ trợ không? Có, từ Claude Code 1.0 trở đi, agent có thể nhận screenshot terminal hoặc UI và phản hồi. Đây là nền tảng cho các agent tự sửa lỗi UI hoặc đọc dashboard giám sát theo phân tích Zylos 2026 (zylos.ai multimodal 2026).
Kết Luận
Claude multi-modal reasoning đã chín đủ để đưa vào production cho hầu hết use case doanh nghiệp Việt, từ kế toán, y tế, kỹ thuật, tới support. Sonnet 4.6 phù hợp khối lượng lớn với chi phí dưới 0.001 USD per ảnh ở quy mô, Opus 4.6 dùng cho tác vụ suy luận sâu chấp nhận trade-off tốc độ và giá. Bước tiếp theo của bạn là đo trên 100-200 image thực tế của domain mình, so sánh ba model, chọn ngưỡng cost-quality, rồi build pipeline có caching và observability ngay từ ngày đầu. Đừng tách image processing và LLM reasoning thành hai service nếu Claude đã giải quyết cả hai trong một call.