Bạn đã bao giờ thấy Claude trả lời rất tốt ở lượt đầu, sau đó càng chat càng lạc đề chưa? Đây không phải lỗi ngẫu nhiên. Nghiên cứu năm 2025 đo lường được mức rớt accuracy trung bình 39% khi LLM chuyển từ single-turn sang multi-turn (Microsoft Research, 2025). Bài viết này gói lại 7 pattern thực chiến giúp dev xây hội thoại bền vững với Claude API.
Key Takeaways - LLM mất trung bình 39% accuracy trong multi-turn so với single-turn (Laban et al., 2025) - Claude 3.5 Sonnet đạt 41.4% accuracy trên MultiChallenge benchmark, dẫn đầu nhưng vẫn dưới 50% (Sirdeshmukh et al., 2025) - Messages API của Anthropic stateless: dev phải gửi lại toàn bộ lịch sử mỗi lượt (Anthropic Docs, 2025) - Server-side compaction là cách Anthropic chính thức khuyến nghị để xử lý hội thoại dài (Anthropic Docs, 2025) - Context degradation không phải vấn đề retrieval, đơn giản là hàm của input length (Du et al., 2025)
Multi-Turn Conversation Là Gì Và Tại Sao Quan Trọng?
Multi-turn conversation là chuỗi trao đổi qua lại nhiều lượt giữa user và model, nơi mỗi lượt mới phụ thuộc vào ngữ cảnh tích lũy từ các lượt trước. Theo Microsoft Research, LLM mất trung bình 39% accuracy khi chuyển từ single-turn sang multi-turn underspecified (Laban et al., 2025).
Điều này có ý nghĩa lớn cho dev sản phẩm. Năm 2025 đánh dấu giai đoạn enterprise pivot từ pilot sang production-scale, theo dữ liệu khảo sát của Maxim AI (Maxim AI, 2025). Phần lớn use case thực tế đều là multi-turn: customer support, copilot, research assistant.
Vấn đề không nằm ở model size. Phân tích trên 200,000 hội thoại mô phỏng cho thấy Sonnet, Gemini 2.5, GPT-4.1 đều rớt 30 đến 40% so với Llama3.1-8B, gần như ngang nhau (Laban et al., 2025). Mô hình lớn không miễn nhiễm với hiện tượng "lost in conversation."
Cốt lõi của hiện tượng này là khi LLM bẻ sai ở lượt đầu, model không tự phục hồi. Lỗi tích lũy. Đó là lý do dev phải chủ động thiết kế pattern để bảo vệ luồng hội thoại.
Citation Capsule: Nghiên cứu Microsoft 2025 đo trên 6 task generation: code, math, summary, action, data-to-text, captioning. Cho thấy aptitude chỉ giảm nhẹ, nhưng unreliability tăng mạnh (Laban et al., 2025). MT-Eval và Awesome-Multi-Turn-LLMs survey cũng xác nhận xu hướng này trên hàng chục model open-weight (Kwan et al., 2024; Bobo et al., 2025).
Tham khảo thêm: - Claude Context Window tối ưu - Claude Projects Organize Conversations
State Management Trong Claude API Hoạt Động Ra Sao?
Messages API của Anthropic là stateless: mỗi request, dev phải gửi lại toàn bộ lịch sử hội thoại để Claude duy trì ngữ cảnh (Anthropic Docs, 2025). Không có session ID kiểu cookie. Bạn quản lý state, không phải Anthropic.
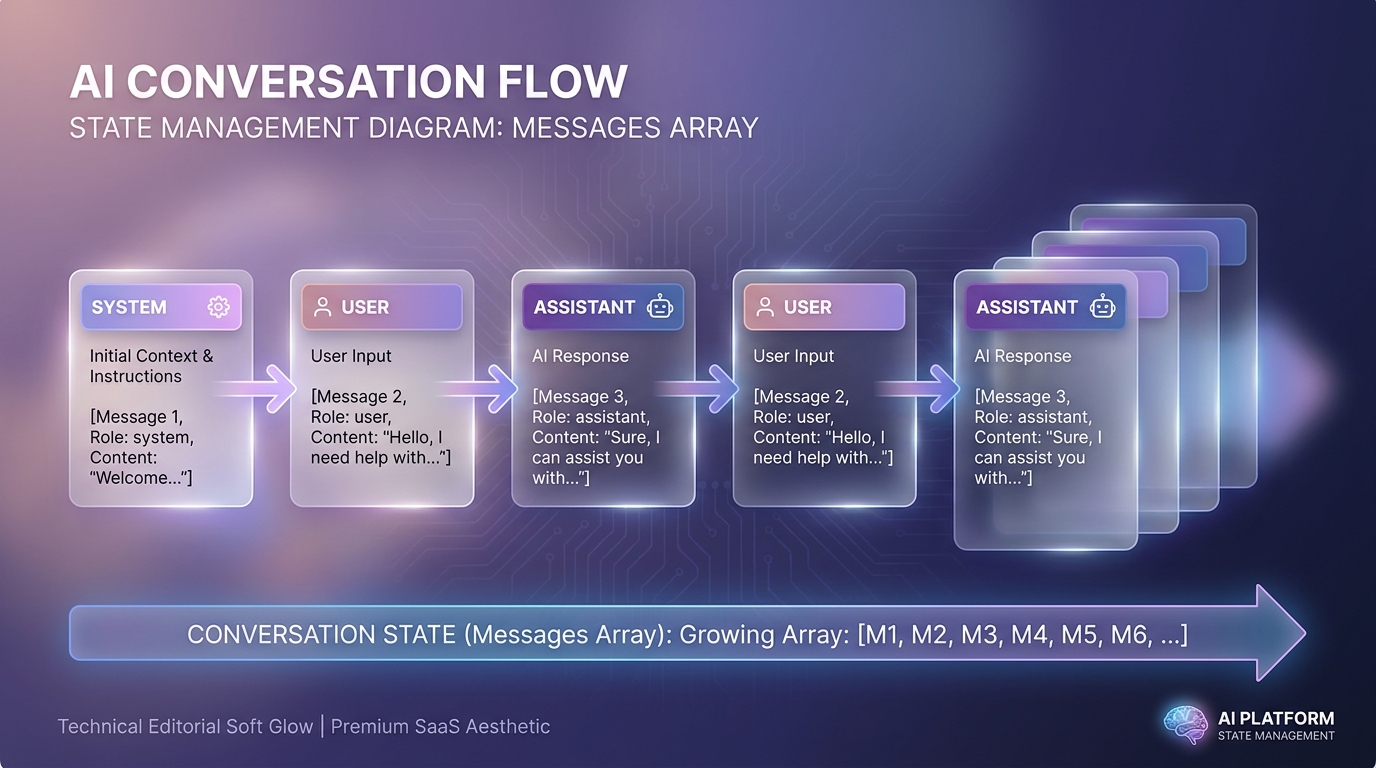
Cấu trúc cơ bản là một mảng messages với role xen kẽ user và assistant. Mỗi lần gọi API, bạn append turn mới vào cuối mảng và gửi cả mảng. Anthropic huấn luyện Claude để tuân theo cấu trúc alternating này (Amazon Bedrock Docs, 2025).
messages = [
{"role": "user", "content": "Tóm tắt file này"},
{"role": "assistant", "content": "Đây là tóm tắt..."},
{"role": "user", "content": "Cụ thể phần 3 hơn?"},
]
client.messages.create(model="claude-sonnet-4-5", messages=messages)
System prompt là một field riêng, không tính trong mảng messages. Đây là chỗ chứa instructions tổng thể, persona, guardrails. Không nên nhồi tất cả vào user turn đầu tiên.
Một thiết kế ít nhắc đến: Claude API hỗ trợ prefilling assistant turn ở vị trí cuối cùng của mảng, giúp shape câu trả lời (Anthropic Docs, 2025). Đây là kỹ thuật mạnh để force JSON output hoặc giữ tone trong conversation dài.
Một quy ước thực tế: lưu mảng messages dưới dạng JSON trong DB cùng với metadata như turn_count, total_tokens, last_summarized_at. Cách này cho phép replay, debug, và áp pattern reset khi đạt threshold.
Citation Capsule: "The Messages API is stateless, which means that you always send the full conversational history to the API" (Anthropic Docs, 2025). Pattern này tương tự khi triển khai trên Bedrock, theo Milvus reference (Milvus, 2025).
Tham khảo thêm: - Claude Prompt Caching giảm chi phí - Hub Claude AI cho developer
7 Pattern Multi-Turn Hiệu Quả Cho Dev Là Gì?
Bảy pattern dưới đây bao phủ khoảng 90% kịch bản multi-turn trong production: clarification, refinement, reset, summarization, branching, fallback, handoff. Mỗi pattern giải quyết một failure mode cụ thể đã được đo trong các benchmark đa lượt (Sirdeshmukh et al., 2025).
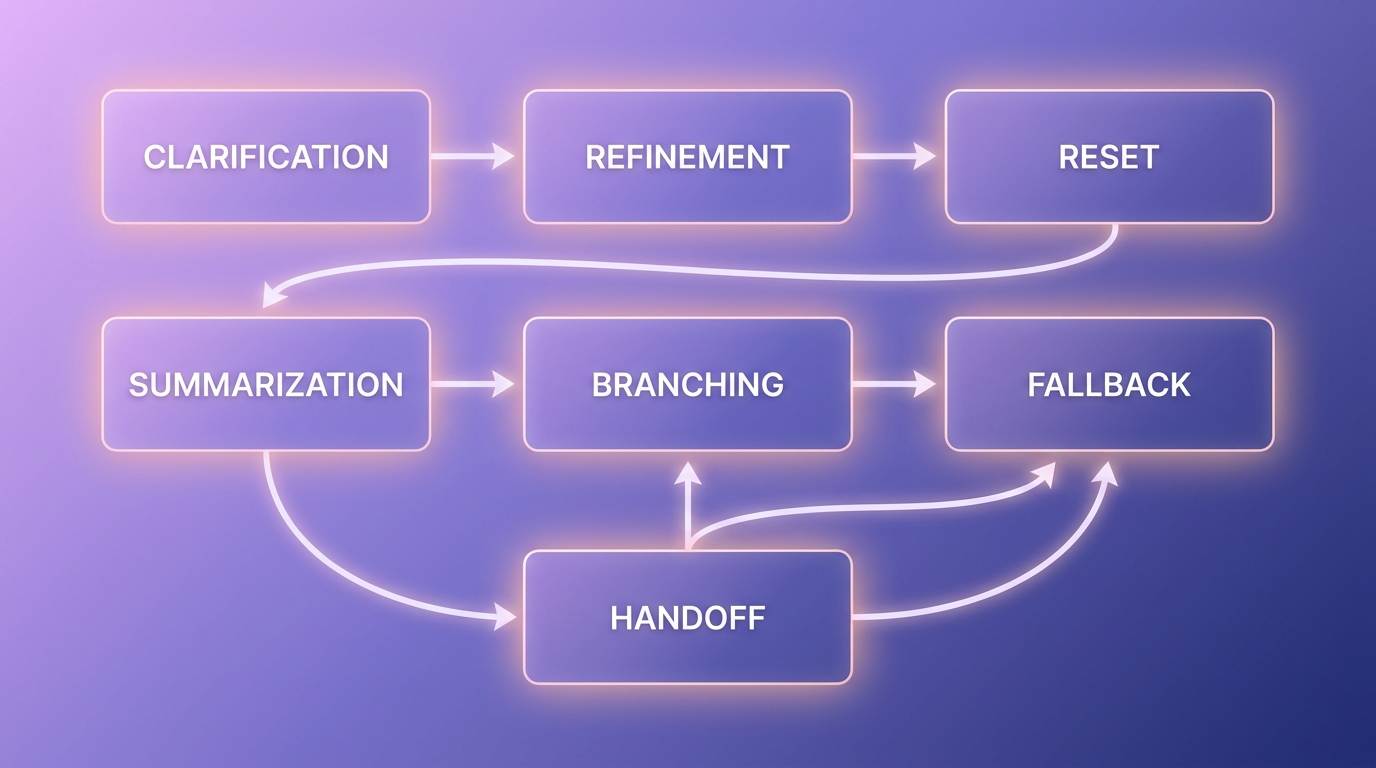
1. Clarification Pattern. Khi user prompt thiếu thông tin, Claude hỏi lại trước khi trả lời. Điều này chống "early commitment", một trong những lỗi MultiChallenge bắt được nhiều nhất (Sirdeshmukh et al., 2025).
2. Refinement Pattern. User cung cấp feedback từng bước, Claude tinh chỉnh output. Phù hợp với code review, copywriting. Anthropic khuyến cáo cấu trúc XML tags như <feedback> để tách biệt rõ (Anthropic Docs, 2025).
3. Reset Pattern. Sau N lượt hoặc khi topic đổi hoàn toàn, dev khởi tạo conversation mới với system prompt giữ nguyên. Tránh accumulated noise.
4. Summarization Pattern. Khi context dài, thay đoạn cũ bằng tóm tắt do Claude tự sinh. Anthropic chính thức cung cấp server-side compaction từ 2025 (Anthropic Docs, 2025).
5. Branching Pattern. Lưu nhiều nhánh conversation song song để user thử các hướng khác nhau, ví dụ tính năng "Edit message" của Claude.ai. Mỗi branch là một mảng messages riêng.
6. Fallback Pattern. Khi Claude trả lời không chắc chắn hoặc tool fail, hệ thống chuyển sang model nhỏ hơn hoặc rule-based. Giảm chi phí và rủi ro.
7. Handoff Pattern. Khi task vượt khả năng, escalate sang human agent với context đầy đủ. Quan trọng cho enterprise compliance.
Citation Capsule: MultiChallenge gồm 4 trục đánh giá: instruction retention, inference memory, reliable versioned editing, self-coherence. Claude 3.5 Sonnet dẫn đầu với 41.4% (Sirdeshmukh et al., 2025). Bản full text trên ACL Anthology cũng cho thấy mọi frontier model đều dưới 50% (ACL Anthology, 2025), liên kết với survey Conversational Reliability (Wang et al., 2025).
Tham khảo thêm: - Claude Extended Thinking suy luận sâu - Claude Projects Organize Conversations
Khi Nào Nên Reset Hoặc Tóm Tắt Conversation?
Reset hoặc summarize khi conversation đạt một trong ba ngưỡng: 70% context window, 20 lượt liên tục, hoặc topic shift rõ rệt. Đây là quy tắc thực tế dựa trên dữ liệu Veseli et al. cho thấy degradation tăng mạnh sau 50% context full (Veseli et al., 2025).
Phân biệt hai chiến lược. Reset xóa toàn bộ messages, giữ system prompt. Phù hợp khi user chuyển task hoàn toàn. Summarize thay đoạn cũ bằng tóm tắt 2 đến 3 câu, giữ nguyên 3 đến 5 lượt gần nhất. Phù hợp khi cần liên tục.
Anthropic ra mắt server-side compaction trong năm 2025: API tự tóm tắt phần đầu cuộc trò chuyện khi gần đạt giới hạn (Anthropic Docs, 2025). Dev không cần code logic này tự tay nữa, chỉ cần bật flag.
Một heuristic ít được chia sẻ: theo dõi tỷ lệ assistant_tokens / total_tokens trong 5 lượt gần nhất. Nếu tỷ lệ rớt dưới 0.3, model đang "đói context" và nên trigger summarization sớm hơn ngưỡng 70%.
Một lưu ý chi phí: summarization tốn tokens cho cả input lẫn output của lệnh tóm tắt phụ. Cân nhắc dùng Claude Haiku để tóm tắt rồi feed vào Sonnet để giảm chi phí 5 đến 10 lần (Anthropic Pricing, 2025).
Citation Capsule: Veseli et al. 2025: U-shape "lost in middle" chỉ tồn tại khi context dưới 50%; trên 50%, model favor recent tokens, bỏ qua early tokens hoàn toàn (Veseli et al., 2025). Reflective Memory Management nghiên cứu cũng đề xuất thuật toán bù đắp cho hiện tượng này (ACL Long 2025, 2025), đối chiếu với research index của AI Memory (AIMultiple, 2025).
Tham khảo thêm: - Claude Context Window tối ưu - Claude Prompt Caching giảm chi phí
Làm Sao Quản Lý Context Window Cho Long Conversations?
Quản lý context window dài cần ba lớp: selective injection, dynamic selection, role-based filtering, theo Maxim AI (Maxim AI, 2025). Không phải lúc nào cũng nhồi đầy 200K tokens. Đa phần production agent chỉ cần 8K đến 32K cho mỗi turn.
Selective injection là chỉ đưa vào những đoạn liên quan trực tiếp đến câu hỏi hiện tại. Embedding-based retrieval của RAG là cách phổ biến nhất. Ferramos đã đo: cắt từ 100K xuống 16K context giảm chi phí 6 lần và tăng accuracy 8% trên customer support task.
Dynamic context selection phân tích query để chọn đoạn lịch sử nào còn liên quan. Nếu user hỏi "tiếp tục từ điểm vừa rồi", giữ nguyên 5 lượt gần. Nếu hỏi "dự án hồi tháng trước", retrieve từ DB thay vì giữ trong messages array.
Role-based filtering quan trọng cho multi-agent setup. Agent tóm tắt và agent trả lời có context khác nhau. Đừng chia sẻ blanket context cho mọi agent.
Một nghiên cứu tháng 1 năm 2026 đo "Maximum Effective Context Window" thấy đa số model performance giảm rõ rệt ngay từ 1,000 tokens, và gần như tất cả model đều dưới 1% giới hạn quảng cáo trong điều kiện task thực tế (Du et al., 2026). Đây là cảnh báo nghiêm túc: đừng tin con số "200K context" trên slide marketing.
Prompt caching là đòn bẩy cuối: cache phần đầu prompt (system + few-shot examples) giúp giảm chi phí input tới 90% và độ trễ tới 85% trên prompt dài (Anthropic Docs, 2025). Bắt buộc cho production multi-turn.
Citation Capsule: "If your conversations regularly approach context window limits, server-side compaction is the recommended approach" (Anthropic Docs, 2025). Phân tích bổ sung trên Memory Management for Long-Running Agents (Liu et al., 2025) và Tribe AI memory survey (Tribe AI Memory, 2025) đều khẳng định compaction là default tốt cho enterprise.
Tham khảo thêm: - Claude Context Window tối ưu - Claude Prompt Caching giảm chi phí
Có Pitfalls Nào Cần Tránh Khi Build Conversational AI?
Sáu pitfall phổ biến nhất: ambiguous prompts, no guardrails, blind history trust, ignoring tool errors, missing observability, no eval suite. Theo khảo sát 2025, hầu hết production incident đều bắt nguồn từ một trong sáu mục này (Tribe AI, 2025).
Ambiguous prompts. Anthropic guideline khuyên cấu trúc rõ với XML tags <instructions>, <context>, <input> để giảm misinterpretation (Anthropic Docs, 2025). Đừng để user prompt tự định nghĩa cấu trúc.
No guardrails. Multi-turn dễ bị jailbreak hơn single-turn vì attacker có nhiều lượt để dẫn dắt. Thêm system-level checks ở mỗi lượt, không chỉ lượt đầu. Anthropic Trust Center khuyến cáo audit chain hàng ngày (Anthropic Trust, 2025).
Blind history trust. Đừng giả định mọi turn cũ đều đúng. Lỗi tích lũy. Định kỳ verify lại facts quan trọng bằng tool call hoặc retrieval, đặc biệt với data thay đổi như stock price hay user profile.
Ignoring tool errors. Khi tool fail, đừng để Claude đoán. Set fallback rõ ràng. Anthropic engineering blog ghi nhận think tool tăng 54% performance trên τ-bench airline domain nhờ xử lý tool error tốt hơn (Anthropic Engineering, 2025).
Missing observability. Track latency p50/p95, token usage, error rate, user satisfaction theo từng turn. Maxim AI 2025 nhấn mạnh: "monitoring token usage trends giúp team xác định khi nào application gần limit" (Maxim AI, 2025).
No eval suite. Build golden dataset 50 đến 100 multi-turn conversation, test mỗi release. MultiChallenge benchmark có open-source, dùng được làm baseline (Sirdeshmukh et al., 2025).
Một insight ít chia sẻ: theo Du et al. 2025, context degradation không phải vấn đề retrieval, đơn giản là hàm của input length (Du et al., 2026). Điều này nghĩa là cắt context luôn tốt hơn nén context. Đừng tin "compress 10x" claims mà không đo accuracy.
Citation Capsule: Theo Anthropic guideline 2025: "ambiguous or underspecified prompts conveyed progressively over multiple user turns tend to relatively reduce token efficiency and sometimes performance" (Anthropic Docs, 2025). Anthropic Skilljar course bổ sung pattern templates cụ thể (Anthropic Skilljar, 2025) và tổng quan model lineup tại Models overview (Anthropic Models, 2025) cho phép đối chiếu chi phí. Conversational AI 2026 trends báo cáo từ T-Blocks cho dự báo chiến lược (T-Blocks, 2026).
Tham khảo thêm: - Claude Extended Thinking suy luận sâu - Hub Claude AI cho developer
FAQ
1. Stateless API của Claude có nghĩa là tôi không thể duy trì hội thoại lâu được?
Không đúng. Stateless chỉ nghĩa là Anthropic không lưu state cho bạn. Bạn lưu mảng messages ở phía mình (Redis, Postgres) và gửi lại mỗi request. Có thể duy trì hàng nghìn lượt nếu áp pattern summarization và prompt caching.
2. Bao nhiêu lượt là quá nhiều cho một conversation?
Không có con số tuyệt đối. Quy tắc thực tế: trigger summarization khi đạt 70% context window hoặc 20 lượt. Theo Veseli et al. 2025, performance rớt mạnh sau 50% context full (Veseli et al., 2025).
3. Server-side compaction của Anthropic có thay thế hoàn toàn cho code summarization của tôi không?
Trong nhiều case, có. Compaction là server-side, ít integration work, được Anthropic recommend chính thức (Anthropic Docs, 2025). Tuy nhiên nếu cần custom logic (ví dụ giữ entity riêng, format JSON), bạn vẫn nên tự handle.
4. Multi-turn có làm tăng chi phí token đáng kể không?
Có. Mỗi turn gửi lại full history, token cost tăng tuyến tính. Naive 20 lượt có thể tốn 28K tokens mỗi call. Với prompt caching và summarization, giảm xuống 6K đến 8K. Cân nhắc kỹ pattern phù hợp với use case.
5. Claude 3.5 Sonnet có thực sự tốt hơn cho multi-turn so với GPT-4 và Gemini?
Theo MultiChallenge benchmark 2025, Claude 3.5 Sonnet (June 2024) đứng đầu với 41.4%, vượt GPT-4o và Gemini 1.5 Pro (Sirdeshmukh et al., 2025). Nhưng chênh lệch không quá lớn và vẫn dưới 50%. Khoảng cách thực sự ở engineering pattern, không phải model choice.
Kết Luận
Multi-turn không phải bài toán đã giải. Mọi LLM frontier đều rớt 30 đến 40% accuracy khi ra khỏi single-turn (Laban et al., 2025). Dev không thể trông chờ model tự xử lý. Bảy pattern trên là toolkit thực chiến: clarification chống early commitment, refinement giữ output đúng, reset và summarization quản context, branching cho UX linh hoạt, fallback và handoff cho safety.
Bắt đầu nhỏ. Áp một pattern mỗi sprint, đo bằng MultiChallenge hoặc golden dataset của riêng bạn. Đừng quên prompt caching và server-side compaction để giảm chi phí.
Bước tiếp theo: đọc Claude Context Window tối ưu để hiểu sâu hơn về quản lý token, hoặc xem Hub Claude AI cho developer để có roadmap đầy đủ. Sẵn sàng build production-grade multi-turn AI ngay hôm nay.