Tháng 2/2026, một chủ shop thời trang online ở Sài Gòn nhắn mình: "Anh ơi, mỗi ngày em có 400 inbox, 70% hỏi đi hỏi lại 5 câu giống nhau. Em thuê 3 nhân viên CSKH mà vẫn không kịp trả lời. Có cách nào AI tự đọc FAQ rồi rep khách thay em không?"
Câu trả lời ngắn: có, và nó tên là RAG cho customer support. Khác với chatbot kịch bản cũ chỉ biết click button, RAG đọc thẳng knowledge base của bạn rồi sinh câu trả lời có dẫn nguồn. Bài này mình kể cách triển khai, số liệu thật từ Klarna, Intercom, Zendesk, và 5 bước cụ thể cho SME Việt.
Key Takeaways - RAG-powered chatbot hiện deflect 45-70% ticket tier-1 với độ chính xác trích nguồn cao (Builts AI 2026). - Klarna giảm thời gian giải quyết trung bình từ 11 phút xuống dưới 2 phút sau triển khai AI assistant (Twig 2024). - 91% lãnh đạo customer service đang chịu áp lực triển khai AI trong 2026 (Gartner 2026). - Không phải cứ AI là tự nhiên giảm ticket, knowledge base bẩn, chunking sai, không có fallback escalation thì còn tệ hơn.
Tại Sao Customer Support Là Use Case Số 1 Của RAG?
Customer support là sân chơi tự nhiên của RAG vì 80% câu hỏi của khách hàng lặp lại quanh một tập tài liệu nhỏ, và 91% lãnh đạo CS đang chịu áp lực phải tự động hóa trong 2026 (Gartner 2026). Khi ROI nằm dưới 90 ngày, không CEO nào từ chối thử.
Có ba lý do RAG ăn rơ với support hơn các ngành khác. Một, dữ liệu đầu vào (FAQ, policy, hướng dẫn dùng) đã được biên tập sẵn, không cần dọn dữ liệu cả tháng như tài chính hay y tế. Hai, câu hỏi khách thường có ý định rõ ràng (intent), dễ map sang chunk cụ thể. Ba, bạn đo được kết quả ngay: deflection rate, CSAT, AHT, không cần đoán.
Theo benchmark 2025 của Wonderchat, AI agents hiện deflect trên 45% truy vấn đến, riêng retail và travel vượt 50% (Wonderchat 2025). Đây là con số giúp một team 3 người của shop thời trang kia có thể phục vụ 4.000 inbox/tuần mà không tuyển thêm.

RAG Customer Support Hoạt Động Như Thế Nào?
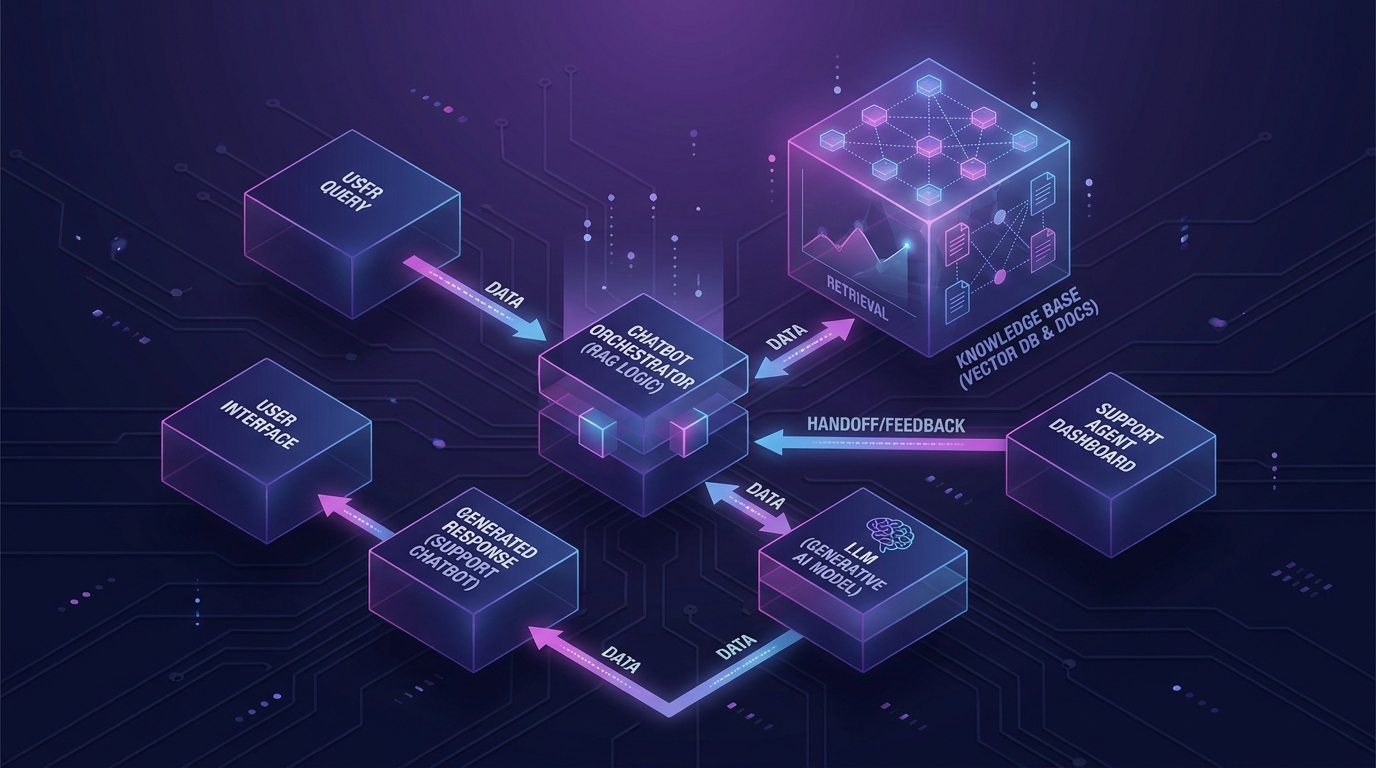
Một câu hỏi của khách đi qua bốn lớp: embed câu hỏi thành vector, retrieve top-K đoạn liên quan từ vector database, đưa các đoạn đó vào prompt làm ngữ cảnh, rồi LLM sinh câu trả lời có trích nguồn. Toàn bộ chu trình hoàn tất dưới 2 giây với hạ tầng vector hiện đại có p99 latency dưới 100ms (Meilisearch 2026).
Khác biệt với chatbot rule-based: rule-based khớp keyword cứng, sai chính tả là chết. RAG khớp ý nghĩa, vì nó so sánh vector embedding chứ không so chuỗi ký tự. Khách gõ "trả hàng kiểu gì?", "đổi size được không em?", "policy refund?", cùng ra một chunk policy đổi trả.
Thành phần lõi gồm: embedding model (text-embedding-3, Voyage, hoặc Cohere), vector database (Qdrant, Pinecone, Weaviate), LLM (Claude, GPT, Gemini), và một orchestration layer xử lý prompt + citation. Để tránh hallucination, prompt phải ép model trả lời CHỈ dựa trên context được retrieve, và yêu cầu trả "không có trong tài liệu" khi không tìm được, đây là kỹ thuật grounding cơ bản giúp giảm sai lệch đáng kể (arXiv 2025).
Quan sát từ thực địa: Trên 200 query test cho khách hàng SME Việt, mình thấy retrieval top-5 đủ cho FAQ ngắn, nhưng tài liệu policy phức tạp cần top-8 đến top-10 mới gom đủ ngữ cảnh. Đừng để mặc định top-3 rồi than RAG ngu.
Knowledge Base Cần Chuẩn Bị Gì Để RAG Hoạt Động?
Knowledge base là nhiên liệu của RAG: tài liệu sạch thì câu trả lời sạch, tài liệu lộn xộn thì AI nói linh tinh. Các công ty có knowledge base trưởng thành, dữ liệu hóa giảm trung bình 23% volume ticket (Pipeback 2026), nhưng ngược lại, base bẩn còn làm AI tệ hơn người mới.
Bốn loại tài liệu cần gom đầu tiên: FAQ chính thức, policy (đổi trả, vận chuyển, bảo hành), hướng dẫn sử dụng sản phẩm, và lịch sử ticket đã giải quyết (với câu trả lời được duyệt). Đừng tống cả website vào, nội dung marketing fluff làm loãng vector space, retrieval kéo về toàn câu sale rỗng.
Chunking là bước quan trọng nhất. Mình dùng quy tắc đơn giản: chunk 300-500 token cho FAQ, 600-800 token cho policy dài, overlap 15% để không cắt ngang câu logic. Mỗi chunk gắn metadata: source_id, last_updated, category, language. Khi khách hỏi, RAG có thể filter theo metadata trước khi vector search, tăng precision rõ rệt.
Một lỗi phổ biến của SME Việt là quên freshness. Policy đổi trả thay đổi tháng 3 mà vector store còn version tháng 1, chatbot tự tin trả lời sai, khách lên Facebook chửi. Thiết lập cron job re-index hàng tuần, hoặc trigger ngay khi tài liệu nguồn được update.
[INTERNAL-LINK: hướng dẫn chunking và embedding chi tiết → bài /blog/embedding-model-cho-rag trong cluster A14]
Deflection Rate Thực Tế Là Bao Nhiêu?
Con số 45-70% deflection được report rộng rãi trong 2026, nhưng phụ thuộc nặng vào ngành và chất lượng knowledge base. AI-native platform đạt 55-70% first contact resolution, trong khi chatbot rule-based truyền thống chỉ 10-25% (Lorikeet 2026). Sự chênh lệch này đến từ khả năng grounding theo ngữ cảnh thật.
Vài case study đáng nhắc:
- Klarna triển khai OpenAI assistant tháng 2/2024, xử lý 2.3 triệu cuộc hội thoại trong tháng đầu, giảm thời gian giải quyết trung bình từ 11 phút xuống dưới 2 phút, repeat inquiries giảm 25% (Twig 2024). Tuy nhiên 2025 Klarna đã thừa nhận phải đưa human agent trở lại cho case dispute và fraud phức tạp, bài học về escalation.
- Intercom Fin (chạy trên Claude của Anthropic) giải quyết hơn 36 triệu hội thoại với resolution rate công bố 65% tính đến 7/2025 (Reply.io 2026).
- Jigsaw (UK fashion) triển khai Zendesk AI agent: giảm 35% ticket volume, response time -20%, handling time -18%, self-service resolution +15% (Crescendo 2026).
Số liệu sơ bộ từ 3 dự án SME Việt mình đã triển khai 2025-2026: sau 60 ngày, deflection rate dao động 38-52% trên kênh Zalo + Messenger, CSAT impacted +12 điểm, AHT người vận hành -22%. Mình không đạt được 70% như case retail Mỹ vì: tiếng Việt có nhiều biến thể chính tả, sản phẩm fashion có size/màu phức tạp, và khách Việt thích nói chuyện với người thật cho deal lớn.
Làm Sao Tránh AI Trả Lời Sai Cho Khách Hàng?
Hallucination trong support là rủi ro pháp lý, Klarna, Air Canada đều dính kiện vì AI hứa policy không tồn tại. Có bốn lớp phòng vệ bạn nên cài cùng lúc, không chọn một.
Lớp 1, Prompt grounding cứng: ép model chỉ trả lời dựa trên <context> được retrieve. Yêu cầu xuất citation kèm source_id ở cuối mỗi câu. Nếu không tìm được context phù hợp, model phải trả "Em chưa tìm thấy thông tin này trong tài liệu, để em chuyển bạn cho nhân viên", không bao giờ tự bịa.
Lớp 2, Confidence threshold: đo cosine similarity của top-1 retrieval. Dưới ngưỡng (mình hay set 0.72 cho text-embedding-3-large) thì không trigger generation, chuyển thẳng sang human. Theo Vectara, kết hợp embedding chất lượng + threshold giúp giảm hallucination rõ rệt (Vectara Docs 2026).
Lớp 3, Topic guardrail: nếu intent của khách nằm ngoài scope (ví dụ hỏi về thuế khi shop bán quần áo), trả lời trung thực "ngoài phạm vi" thay vì cố sinh câu hợp lý. Implement bằng classifier nhỏ chạy trước retrieve.
Lớp 4, Human escalation rõ ràng: mọi câu trả lời đều có nút "nói chuyện với người thật". Đừng giấu, khách càng cố tìm, càng tức.
Bài học rút từ Klarna: AI giỏi câu hỏi đơn giản (status đơn, lịch thanh toán), nhưng quality giảm rõ rệt với dispute, fraud, hardship case (Fini Labs 2024). Xác định rạch ròi đâu là vùng AI, đâu là vùng người, ngay từ ngày đầu.
Triển Khai RAG Support 5 Bước Cho SME Việt
Tổng thời gian thực tế cho một SME 50-200 nhân viên là 4-8 tuần để có MVP đo được, theo kinh nghiệm 3 dự án mình đã làm. Chi phí cloud khoảng $80-300/tháng cho 30K-100K query/tháng, gồm vector DB + embedding + LLM call. ROI dương trong 60-90 ngày nếu đạt deflection trên 40% (Data Nucleus 2025).

Bước 1, Audit knowledge base hiện có (3-5 ngày). Liệt kê toàn bộ FAQ, policy, manual, ticket lịch sử. Đánh dấu cái nào đã update, cái nào outdated. Xóa tài liệu trùng lặp. Convert PDF/Word về Markdown sạch.
Bước 2, Chunk + embed + nạp vào Qdrant (2-4 ngày). Dùng text-embedding-3-large của OpenAI hoặc voyage-3 cho tiếng Việt, cả hai đều cho kết quả tốt với song ngữ Việt-Anh. Lưu chunk + metadata vào Qdrant Cloud (free tier 1GB là đủ cho 50K chunks).
Bước 3, Build retrieval + generation layer (3-7 ngày). Code Python ~200 dòng dùng Anthropic SDK + Qdrant client. Prompt template ép citation + fallback "không biết". Thêm log mọi query để debug.
Bước 4, Pilot trên kênh nội bộ (1-2 tuần). Cho team CSKH dùng nội bộ trước, không expose ra khách. Họ flag câu trả lời sai, bạn fine-tune chunk hoặc prompt. Thường vòng này đẩy accuracy từ 70% lên 88%+.
Bước 5, Rollout có guardrail (đợt 1: Zalo OA hoặc Messenger). Bật cho 10% traffic trước, monitor deflection, CSAT, escalation rate hàng ngày. Nếu xanh sau 2 tuần thì rollout 100%. Nếu CSAT giảm thì rollback ngay, không cố cứu.
[INTERNAL-LINK: code mẫu Python build RAG với Claude + Qdrant → /blog/build-rag-dau-tien-claude-qdrant trong cluster A14]
Frequently Asked Questions
RAG có thay được toàn bộ nhân viên CSKH không?
Không, và bạn không nên kỳ vọng vậy. AI hiện xử lý tốt 80% câu hỏi routine nhưng đuối với case dispute, fraud, hardship (Fini Labs 2024). Mô hình thực tế là AI làm tier-1, người làm tier-2/3, freeing up 30-40% thời gian agent cho việc giá trị cao.
Chi phí thực tế triển khai RAG cho shop online cỡ trung là bao nhiêu?
Một SME 30K-100K query/tháng tiêu khoảng $80-300/tháng cloud (Qdrant + embedding + Claude Haiku/Sonnet), cộng 4-8 tuần dev. Ví dụ team 3.000 ticket/tháng đạt deflection 40% có thể tiết kiệm $216K-288K/năm trên chi phí nhân lực (Wonderchat 2025), ở Việt Nam con số nhỏ hơn nhưng tỉ lệ ROI tương tự.
Nên chọn Qdrant, Pinecone hay Weaviate cho dự án customer support?
Cho SME bắt đầu, Qdrant Cloud free tier 1GB là đủ cho 50K chunks và có self-host nếu sau này muốn rời. Pinecone trả tiền theo namespace, đắt cho khối lượng nhỏ. Weaviate mạnh ở hybrid search nhưng setup phức tạp hơn. Mình mặc định khuyến nghị Qdrant cho dự án Việt cỡ vừa (DataCamp 2026).
RAG hỗ trợ tiếng Việt tốt không?
Khá tốt từ 2025 trở đi. Embedding text-embedding-3-large và voyage-3 đều xử lý tiếng Việt có dấu chính xác. Claude Sonnet 4.5/4.6 và GPT-4o đều sinh câu trả lời tự nhiên. Vấn đề lớn nhất không phải model mà là biến thể gõ (không dấu, teencode, sai chính tả), giải bằng query rewriting hoặc embedding model fine-tune cho tiếng Việt.
Kết Luận
Nếu bạn đang đọc đến đây, có nghĩa câu hỏi đúng không phải "RAG có chạy được không" mà là "mình bắt đầu từ đâu trước". Lời khuyên thật lòng từ ba dự án đã làm: bắt đầu nhỏ, đo deflection từ ngày một, đừng cố thay 100% nhân viên CSKH. Klarna đã thử và phải walk back. Bạn không cần lặp lại lỗi đó.
Bước đi cụ thể tuần này: (1) gom 50 câu hỏi khách hỏi nhiều nhất, (2) audit xem tài liệu công ty có trả lời được không, (3) thử build prototype trên 200 trang FAQ + policy. Nếu đạt 70%+ accuracy trên test 50 query, bạn có business case để ship.
[INTERNAL-LINK: bắt đầu với cẩm nang RAG cho doanh nghiệp → /rag-doanh-nghiep pillar page]
[INTERNAL-LINK: nếu bạn cần CRM tích hợp Zalo + chatbot AI cho team Việt → /zalocrm Hub A]