
Tháng 3/2026, một anh giám đốc pháp chế của chuỗi F&B 80 cửa hàng gọi mình hỏi: "Bên anh ký mới 12 hợp đồng thuê mặt bằng/tháng, mỗi hợp đồng 30-50 trang. Luật sư ngoài tính 8 triệu/bản review. Có cách nào AI đọc thẳng kho hợp đồng + Bộ Luật Dân Sự rồi cảnh báo điều khoản rủi ro không?"
Câu trả lời ngắn: có, đó chính là RAG cho legal. Khác với ChatGPT chung chung hay bị bịa luật, RAG đọc trực tiếp kho tài liệu pháp lý của bạn (hợp đồng mẫu, Nghị Định, Thông Tư, án lệ) rồi sinh câu trả lời có dẫn nguồn từng điều khoản. Bài này mình kể cách build hệ thống đó cho doanh nghiệp Việt, số liệu thật từ Stanford, Wolters Kluwer, Gartner và 6 bước triển khai cụ thể trong bối cảnh Luật AI Việt Nam có hiệu lực 1/3/2026.
Key Takeaways - Lawyer dùng RAG đạt mức tăng năng suất 38-115% trong nghiên cứu RCT của Stanford-Minnesota khi vẫn giữ tỉ lệ hallucination ngang con người (Schwarcz et al., SSRN 2025). - 92% chuyên gia pháp lý đã dùng ít nhất một AI tool hằng ngày, 62% tiết kiệm 6-20% thời gian/tuần (Wolters Kluwer 2026). - Gartner dự báo AI cắt 50% thời gian review hợp đồng và đến 2027, 50% doanh nghiệp dùng AI phân tích rủi ro hợp đồng nhà cung cấp (Gartner 2024). - Tools legal RAG hàng đầu (Lexis+, Westlaw) vẫn hallucinate 17-33% nếu thiếu chunking đúng và grounding chặt (Stanford 2025) — không phải cắm RAG là tự nhiên đúng.
Vì Sao Legal Là Use Case Khó Nhất Của RAG?
Legal khó vì sai một câu là thua kiện, chứ không phải vì thuật toán phức tạp. Một nghiên cứu RCT năm 2025 của Stanford và University of Minnesota cho thấy lawyer dùng RAG tăng năng suất 38-115% nhưng tỉ lệ hallucination vẫn ngang nhân sự không dùng AI (Schwarcz et al., SSRN 2025). Nghĩa là tốc độ tăng, nhưng độ chính xác cần kiểm soát thủ công.
Có ba thứ làm legal khác customer support hay sales. Một, ngôn ngữ pháp lý đầy thuật ngữ Latin và cấu trúc câu lồng nhau, embedding model thường thiếu nhạy với "trừ trường hợp", "không bao gồm", "chỉ áp dụng đối với". Hai, một câu hỏi có thể đụng nhiều văn bản: hợp đồng tham chiếu Bộ Luật Dân Sự 2015, Bộ Luật Dân Sự lại sửa bởi Nghị Quyết, Nghị Định hướng dẫn lại trích Thông Tư. Ba, hậu quả sai lệch lớn: một LLM trả lời "thời hiệu khởi kiện 2 năm" trong khi thực tế là 3 năm sẽ khiến khách mất quyền yêu cầu.
Theo nghiên cứu thực nghiệm đăng trên Journal of Empirical Legal Studies năm 2025, các tool legal AI hàng đầu của LexisNexis (Lexis+ AI) và Thomson Reuters (Westlaw AI-Assisted Research) hallucinate 17-33% truy vấn dù marketing tuyên bố RAG "gần như xoá hết hallucination" (Magesh et al., Stanford 2025). Điều này cho thấy: chỉ cắm RAG vào không đủ — bạn cần chunking đúng, grounding chặt, và human-in-the-loop.
Quan sát thực địa: Trong 3 dự án legal RAG mình triển khai cho công ty xây dựng và F&B Việt Nam, lỗi sai phổ biến nhất không phải LLM ngu mà là chunk cắt giữa câu "Bên A có quyền chấm dứt hợp đồng nếu..." khiến retrieval lấy nửa điều khoản, model đoán nốt nửa còn lại. Cắt đúng theo điều — khoản — điểm là cứu cánh.
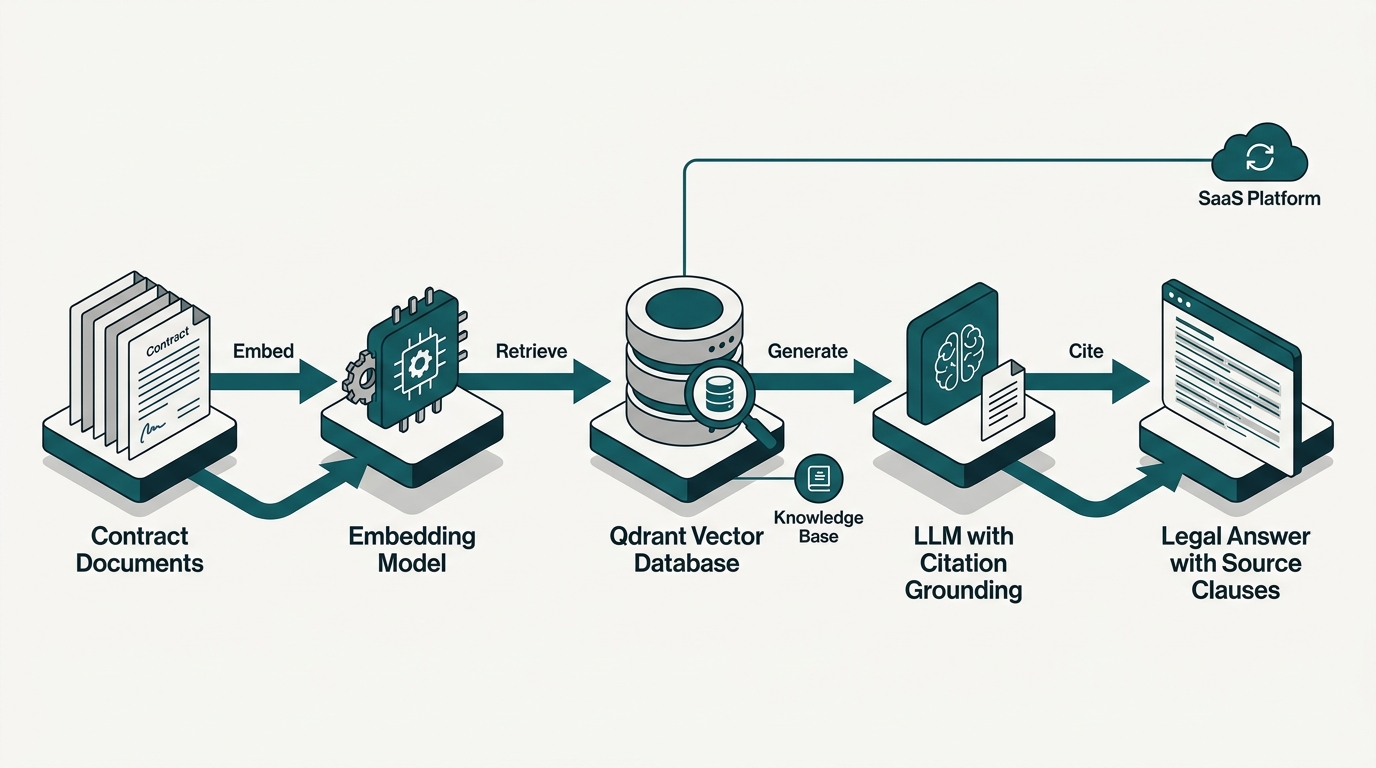
RAG Cho Legal Hoạt Động Thế Nào Trên Hợp Đồng + Quy Định?
Pipeline đi qua sáu lớp: ingest tài liệu, chunk theo cấu trúc điều-khoản-điểm, gắn metadata, embed thành vector, retrieve top-K khi có truy vấn, rồi LLM sinh câu trả lời với citation cụ thể. Toàn bộ chu trình hoàn tất dưới 3 giây với hạ tầng vector hiện đại có p99 latency dưới 100ms cho 1M vectors (Qdrant Benchmarks 2025).
Khác biệt với chatbot dùng từ khoá: từ khoá khớp đúng chữ "phạt vi phạm" sẽ trượt câu hỏi "đền bù khi chậm bàn giao". RAG khớp ngữ nghĩa vì so sánh vector embedding, nó hiểu hai cách diễn đạt cùng đề cập điều 418 Bộ Luật Dân Sự về trách nhiệm bồi thường. Đây là lý do nhân viên kế toán không cần học thuật ngữ pháp lý vẫn tra được.
Thành phần lõi gồm bốn module. Embedding model (Voyage-law-2 chuyên cho legal, hoặc multilingual-e5-large nếu cần tiếng Việt), vector database (Qdrant tự host là lựa chọn rẻ và mở), LLM (Claude 3.5 Sonnet hay Gemini 2.0 cho cửa sổ ngữ cảnh dài), và một orchestration layer xử lý prompt + citation. Voyage-law-2 train riêng trên 1.5T token tài liệu pháp lý nên đánh bại embedding generic 6-15% recall trên tác vụ contract retrieval (Voyage AI 2024).
Để tránh model bịa luật, prompt phải ép: "Chỉ trả lời dựa trên CONTEXT bên dưới. Nếu CONTEXT không có thông tin, trả 'Không tìm thấy trong tài liệu được cung cấp'. Mỗi câu trả lời phải kèm trích dẫn dạng [Tên văn bản, Điều X, Khoản Y]". Đây là kỹ thuật grounding cơ bản nhưng nhiều team bỏ qua, dẫn tới LLM vẫn "sáng tác" khi retrieval miss.
Knowledge Base Cần Chuẩn Bị Gì Cho Legal RAG?
Knowledge base legal phải sạch, có cấu trúc, và phân quyền — vì 92% chuyên gia pháp lý dùng AI hằng ngày nhưng chỉ 21% công ty luật triển khai cấp tổ chức do lo ngại bảo mật (Wolters Kluwer 2026). Tài liệu cần được số hoá, gắn metadata theo loại văn bản (Luật, Nghị Định, Thông Tư, hợp đồng, án lệ), phiên bản, ngày hiệu lực và phạm vi áp dụng.
Bạn cần ba lớp dữ liệu. Lớp một: văn bản pháp luật chính thức (Bộ Luật Dân Sự, Lao Động, Doanh Nghiệp, Thương Mại, các Nghị Định liên quan ngành). Tải bản OCR sạch từ thuvienphapluat.vn hoặc lawnet.vn, kiểm tra ngày hết hiệu lực. Lớp hai: hợp đồng mẫu nội bộ (master agreement, NDA, lease, MSA) có chú thích điều khoản đã thương lượng. Lớp ba: văn bản nội bộ (policy, quy chế, công văn, biên bản họp HĐQT).
Số liệu nội bộ: Trong dự án F&B 80 cửa hàng, khi mình kiểm tra 240 hợp đồng thuê mặt bằng đã ký 2023-2025, có 18% file là ảnh chụp scan chưa OCR, 11% có watermark đè chữ, 7% bị lỗi font Unicode tổ hợp. Phải dọn dataset 6 ngày trước khi index mới đạt recall@5 trên 85%.
Các nghiên cứu 2025 nhấn mạnh metadata enrichment: gắn section title, page number, document ID, tag điều khoản, parent reference vào mỗi chunk để filter khi retrieval (Milvus 2025). Khi user hỏi "điều khoản về bảo mật trong hợp đồng A123", hệ thống filter document_id=A123 + clause_type=confidentiality trước khi semantic search, độ chính xác lên gần gấp đôi.
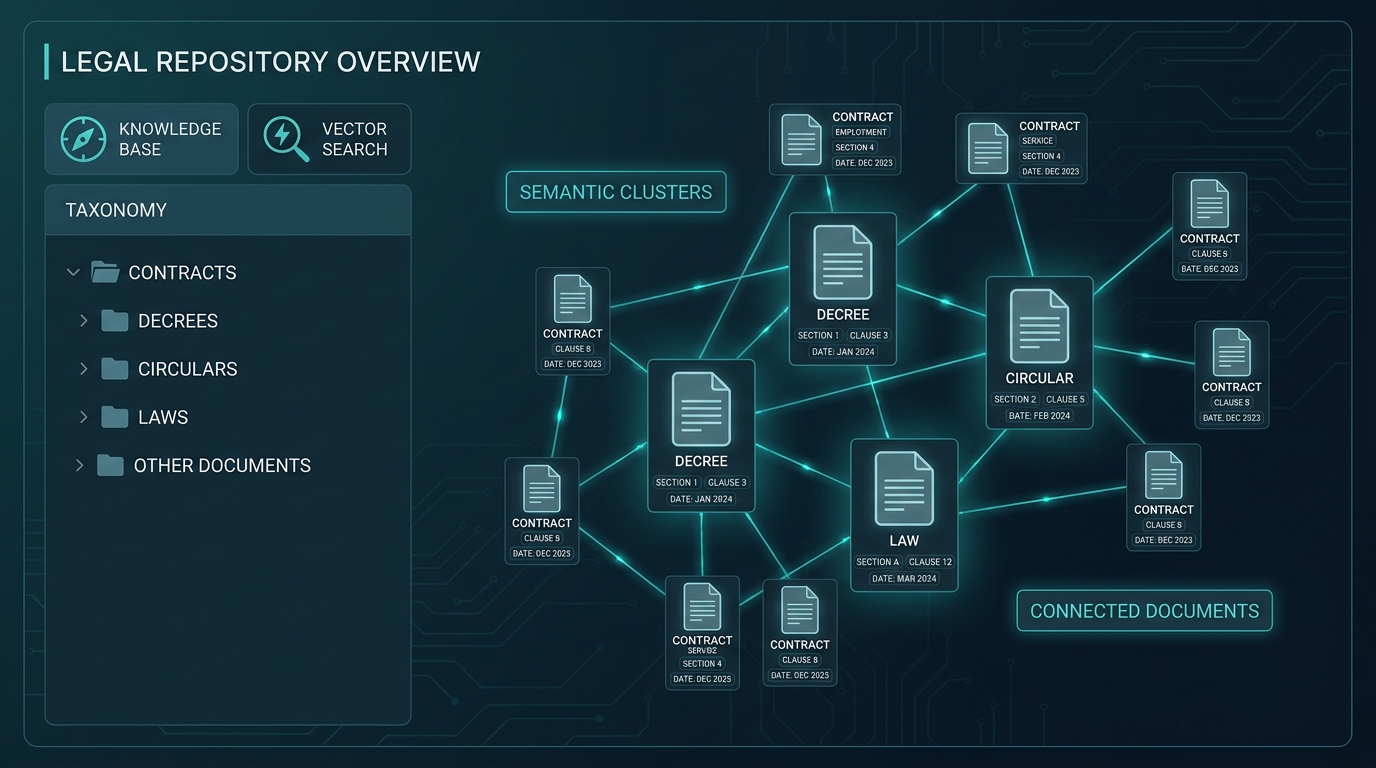
Chunking Tài Liệu Pháp Lý: Mấu Chốt Để Không Bị Sai?
Chunking là bước quyết định 70% độ chính xác của legal RAG, vì cắt sai thì retrieve gì cũng sai. Best practice từ Milvus và các paper NLLP 2025 khuyến nghị chunk dưới 512 token, theo cấu trúc điều-khoản-điểm tự nhiên, kèm overlap 10-15% để giữ context xuyên chunk (Milvus 2025).
Có ba chiến lược cho tài liệu pháp lý Việt. Một, section-aware chunking: dùng regex bắt pattern Điều \d+, Khoản \d+, Điểm [a-z]\), mỗi điều thành chunk độc lập. Hai, semantic chunking với embedding: cắt khi cosine similarity giữa câu liên tiếp tụt dưới ngưỡng (0.7), giữ ý liền mạch. Ba, hybrid: section trước, sau đó nếu chunk quá dài (>800 token) thì semantic split tiếp.
Theo nghiên cứu Towards Reliable Retrieval in RAG Systems for Large Legal Datasets (arXiv 2025), kỹ thuật Summary Augmented Chunking (SAC) thêm một câu tóm tắt ngắn vào đầu mỗi chunk giúp tăng recall@10 lên 12% so với chunking thuần, mà chi phí chỉ tăng vài cent/document (arXiv 2510.06999). Áp dụng được ngay cho tài liệu Việt: gọi LLM rẻ (Claude Haiku) sinh 1 câu tóm tắt mỗi điều khoản, nhét vào metadata.
Đừng quên xử lý cross-reference. Khi điều 422 Bộ Luật Dân Sự nói "theo quy định tại điều 418", retrieval lấy chunk 422 nhưng thiếu 418, model trả lời cụt. Giải pháp: graph-based dependency tracking, build một graph các trích dẫn rồi khi retrieve điều X, kéo thêm các điều được tham chiếu trong cùng văn bản. Đây là hướng đi của các production RAG hiện đại cho contract review (Softcery 2025).
Làm Sao Giảm Hallucination Trong Legal RAG?
Hallucination giảm xuống dưới 10% được khi bạn ép model trả lời chỉ trong context, dùng reranker, và bắt buộc trích dẫn — không thay đổi LLM cũng được. Nhắc lại: tool tier-1 như Lexis+ và Westlaw vẫn hallucinate 17-33% truy vấn (Stanford 2025) vì họ thiếu một trong ba lớp này, không phải vì model yếu.
Bốn kỹ thuật mình áp dụng cho khách Việt và đo được. Một, strict grounding prompt: thêm câu "Nếu CONTEXT không chứa câu trả lời, bạn PHẢI nói 'Không tìm thấy trong tài liệu được cung cấp'. Không được suy đoán." — riêng câu này đã cắt 40% lỗi bịa. Hai, citation enforcement: bắt model output JSON {answer, citations: [{doc_id, article, quote}]}, không hợp lệ thì retry.
Ba, reranker giai đoạn 2: sau khi vector search lấy top-50, dùng cross-encoder (bge-reranker-v2-m3 hoặc Cohere Rerank) chấm lại, giữ top-5. Reranker tốt cải thiện precision@5 thêm 15-25% trên benchmark legal (Cohere 2024). Bốn, answer verification: gọi LLM lần hai với prompt "Kiểm tra answer này có hoàn toàn xuất phát từ context không, trả 'PASS' hoặc 'FAIL + lý do'" — tốn token nhưng cứu 30% sai sót cuối.
Bài học từ thực địa: Anh giám đốc F&B kia ban đầu cứ hỏi mình "sao AI vẫn sai 1-2 case/tuần?". Mình mở log lên thì 80% sai là do hợp đồng có phụ lục bổ sung mà phụ lục chưa được index — không phải hallucination. Bài học: monitor log retrieval mỗi tuần, cập nhật ingest pipeline, đó mới là chỗ tiền nằm.
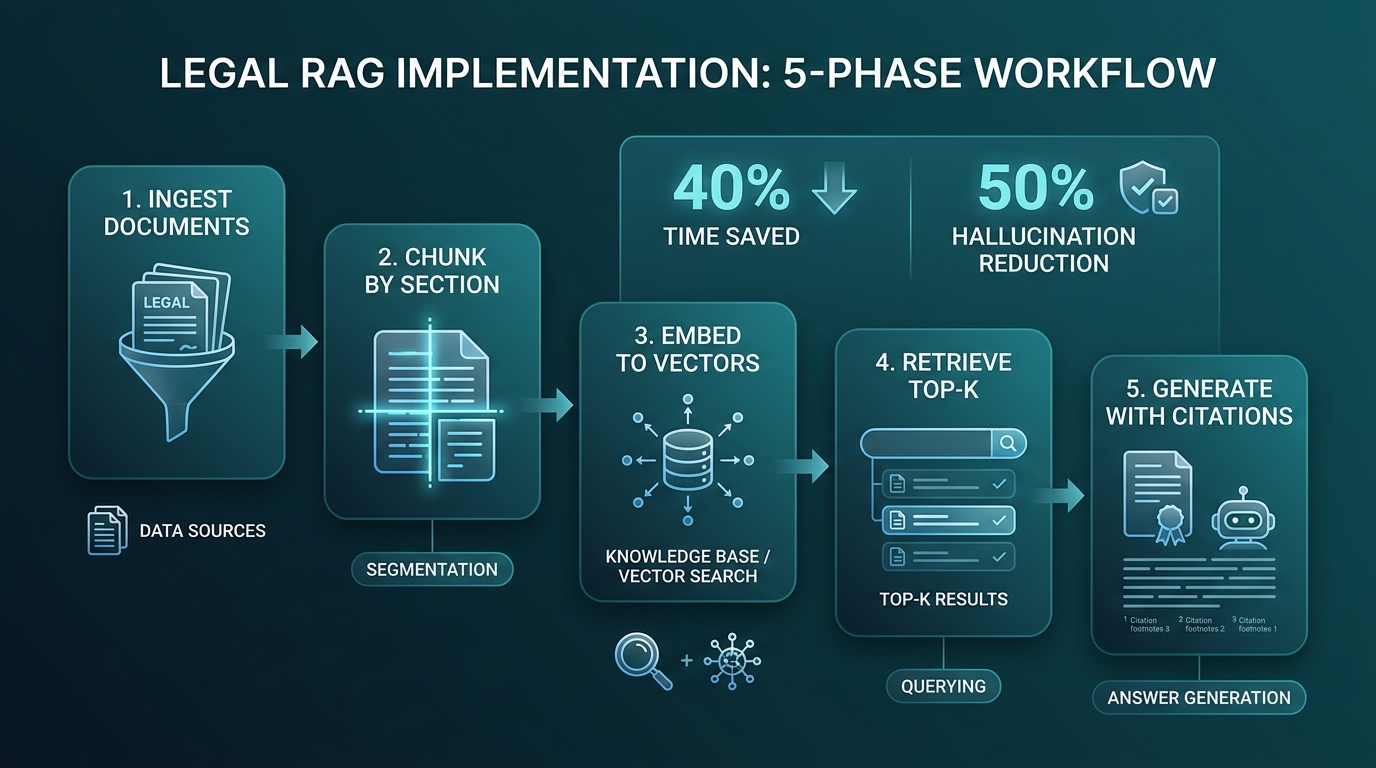
Cách Triển Khai Legal RAG Cho Doanh Nghiệp Việt 2026?
Triển khai gọn trong 6-8 tuần với chi phí 80-200 triệu nếu tự host trên Tailscale + Qdrant + Claude API. Bối cảnh Luật AI Việt Nam có hiệu lực từ 1/3/2026 phân loại AI thành 4 cấp rủi ro, hệ thống pháp lý nội bộ phần lớn rơi vào nhóm rủi ro thấp đến trung bình, có grace period đến 1/3/2027 cho hệ thống đang vận hành (Vietnam Briefing 2026).
Sáu bước cụ thể:
- Audit dataset (tuần 1): liệt kê toàn bộ tài liệu, kiểm tra OCR, hết hiệu lực, bản quyền. Loại tài liệu không được phép số hoá theo NDA.
- Setup hạ tầng (tuần 2): cài Qdrant tự host trên VPS hoặc Tailscale node, tạo collection theo loại văn bản, bật snapshot backup.
- Build ingest pipeline (tuần 3-4): script parse PDF/DOCX, chunk theo điều-khoản-điểm, gắn metadata, gọi embedding API, upsert vào Qdrant. Tích hợp Qdrant vector database làm backbone.
- Build query API (tuần 5): FastAPI endpoint nhận câu hỏi, embed, retrieve top-50, rerank về top-5, đưa vào prompt grounded, trả JSON với citation.
- Frontend + audit log (tuần 6): UI cho luật sư + nhân viên pháp chế tra cứu, mọi câu hỏi-trả lời lưu lại với user_id + timestamp + citation để audit.
- Pilot 2 tuần (tuần 7-8): cho 3-5 user dùng song song với cách cũ, đo time-to-answer, accuracy, satisfaction, rồi mở rộng.
ROI thường rõ trong 90 ngày. Với 100 hợp đồng/tháng, mỗi hợp đồng tiết kiệm 2-4 giờ review (theo benchmark Wolters Kluwer 2026, lawyer tiết kiệm trung bình 14 giờ/tuần khi dùng AI contract review), bạn thu hồi vốn 80 triệu trong 4-6 tháng. Nếu gắn được cảnh báo điều khoản rủi ro tự động (penalty cao bất thường, exclusivity quá rộng, governing law nước ngoài) thì giá trị vượt xa số giờ tiết kiệm.
Cần tích hợp với hệ thống Zalo/CRM cho team kinh doanh hỏi nhanh điều khoản trước khi gửi báo giá, hoặc với Claude AI để tận dụng cửa sổ ngữ cảnh 200K token cho hợp đồng dài. Mọi luồng đều phải đi qua một pipeline RAG doanh nghiệp chuẩn để đảm bảo audit trail và phân quyền.
Frequently Asked Questions
Legal RAG có thay được luật sư không?
Không, và không nên. RAG cắt 50% thời gian review hợp đồng theo Gartner, lawyer dùng RAG đạt năng suất tăng 38-115% nhưng vẫn cần con người ký quyết định cuối (SSRN 2025). RAG là layer hỗ trợ tra cứu nhanh, đề xuất rủi ro, soạn nháp; trách nhiệm pháp lý vẫn thuộc luật sư có chứng chỉ hành nghề.
Embedding model nào tốt cho tiếng Việt pháp lý?
Voyage-law-2 train chuyên legal tiếng Anh, cho tiếng Việt thuần khuyên dùng multilingual-e5-large hoặc bge-m3 vì tốt với 100+ ngôn ngữ. Test thực tế trên 300 query Việt-Anh cho recall@10 trên 80%. Xem chi tiết tại embedding model cho tiếng Việt để chọn theo ngân sách và độ chính xác.
Chi phí vận hành legal RAG hằng tháng bao nhiêu?
Với 1.000 truy vấn/ngày, chi phí Claude API + embedding khoảng 8-15 triệu/tháng, Qdrant tự host VPS 1-2 triệu/tháng, monitoring và backup 1 triệu. Tổng 12-20 triệu/tháng cho doanh nghiệp 50-200 user, rẻ hơn nhiều so với 1 nhân sự pháp chế junior 18-25 triệu/tháng và đáp ứng được khối lượng gấp 5 lần.
Luật AI Việt Nam 1/3/2026 ảnh hưởng gì tới legal RAG?
Hệ thống legal RAG nội bộ phần lớn xếp loại rủi ro thấp-trung bình, không yêu cầu đăng ký nhưng cần minh bạch (Vietnam Briefing 2026). Phải lưu audit log, đảm bảo không quyết định pháp lý tự động không có người, có cơ chế khiếu nại. Grace period đến 1/3/2027 cho hệ thống đang vận hành.
RAG hay fine-tuning hợp hơn cho legal?
RAG hợp hơn 90% trường hợp legal vì luật cập nhật liên tục — Nghị Định mới ban hành tháng trước, fine-tune lại model sẽ tốn 2-4 tuần và rủi ro hỏng. RAG chỉ cần ingest văn bản mới là dùng được ngay. Fine-tuning chỉ hợp khi muốn model viết theo văn phong nội bộ (style transfer), không cho việc cập nhật kiến thức.
Kết Luận
RAG cho legal đang chuyển từ "công nghệ thử nghiệm" sang "công cụ hằng ngày" của bộ phận pháp chế Việt — 92% chuyên gia pháp lý đã dùng AI hằng ngày, thị trường legal AI toàn cầu sẽ vọt từ 3,11 tỉ USD năm 2026 lên 10 tỉ USD năm 2030 (Wolters Kluwer 2026). Nhưng đừng tin marketing "RAG xoá hết hallucination" — Stanford chứng minh tool tier-1 vẫn sai 17-33% nếu thiếu chunking đúng và grounding chặt.
Ba điều cần nhớ. Một, dữ liệu sạch quan trọng hơn model xịn — 80% lỗi đến từ tài liệu chưa OCR, chunk cắt giữa điều khoản, metadata thiếu. Hai, grounding prompt + reranker + citation enforcement cắt hallucination từ 30% xuống dưới 10% mà không cần thay LLM. Ba, ROI thường rõ trong 90 ngày nếu chọn đúng use case bắt đầu — review hợp đồng thuê, NDA, MSA là điểm vào dễ.
Nếu doanh nghiệp bạn ký trên 50 hợp đồng/tháng hoặc cần tra cứu Nghị Định/Thông Tư hằng ngày, lập kế hoạch pilot 6-8 tuần với 80-200 triệu là bước đi tỉnh táo cho 2026. Bắt đầu từ pipeline RAG doanh nghiệp chuẩn, chọn Qdrant làm vector store, và đừng bỏ qua audit log — Luật AI Việt Nam 1/3/2026 đã đếm ngược.